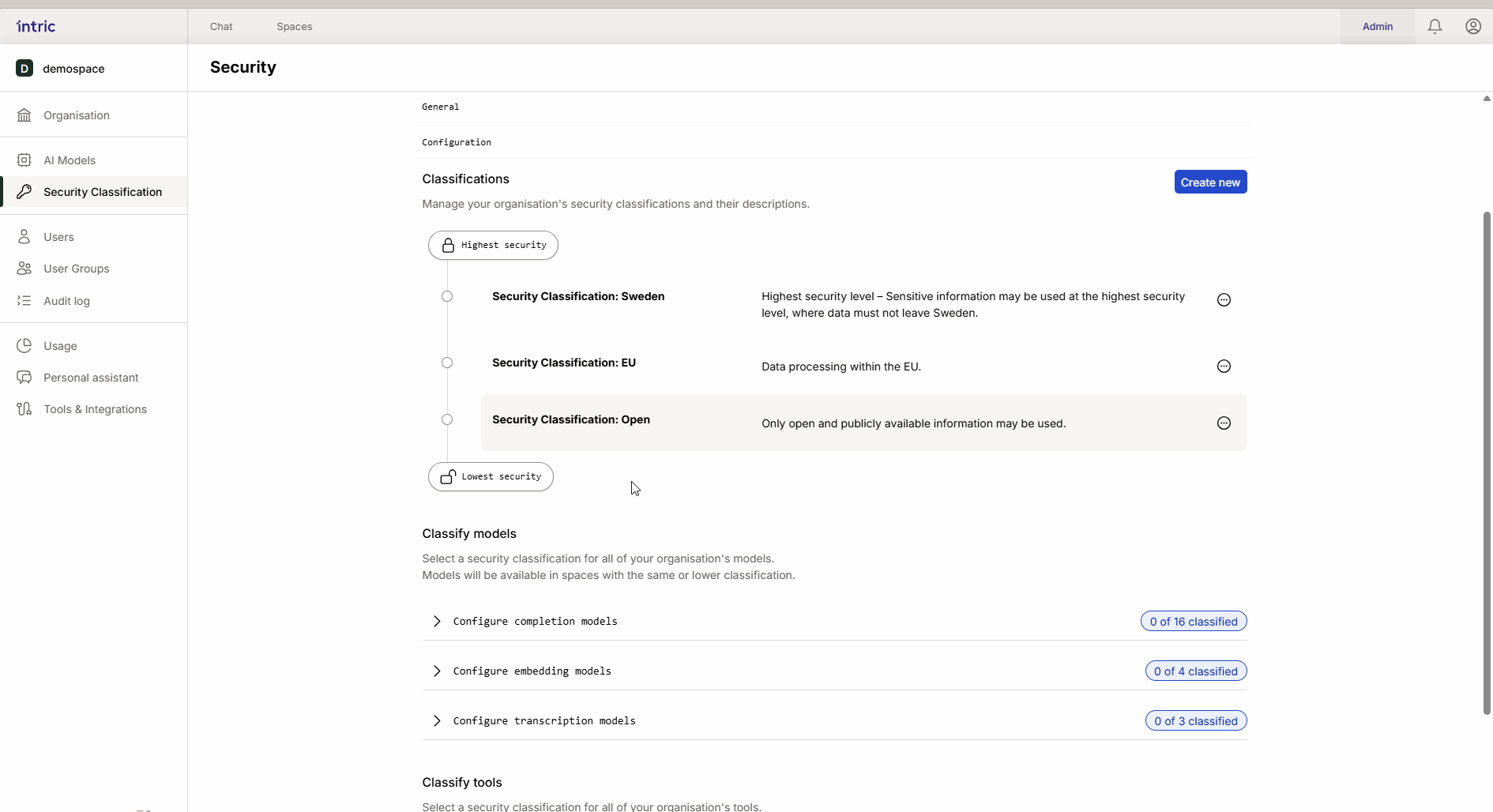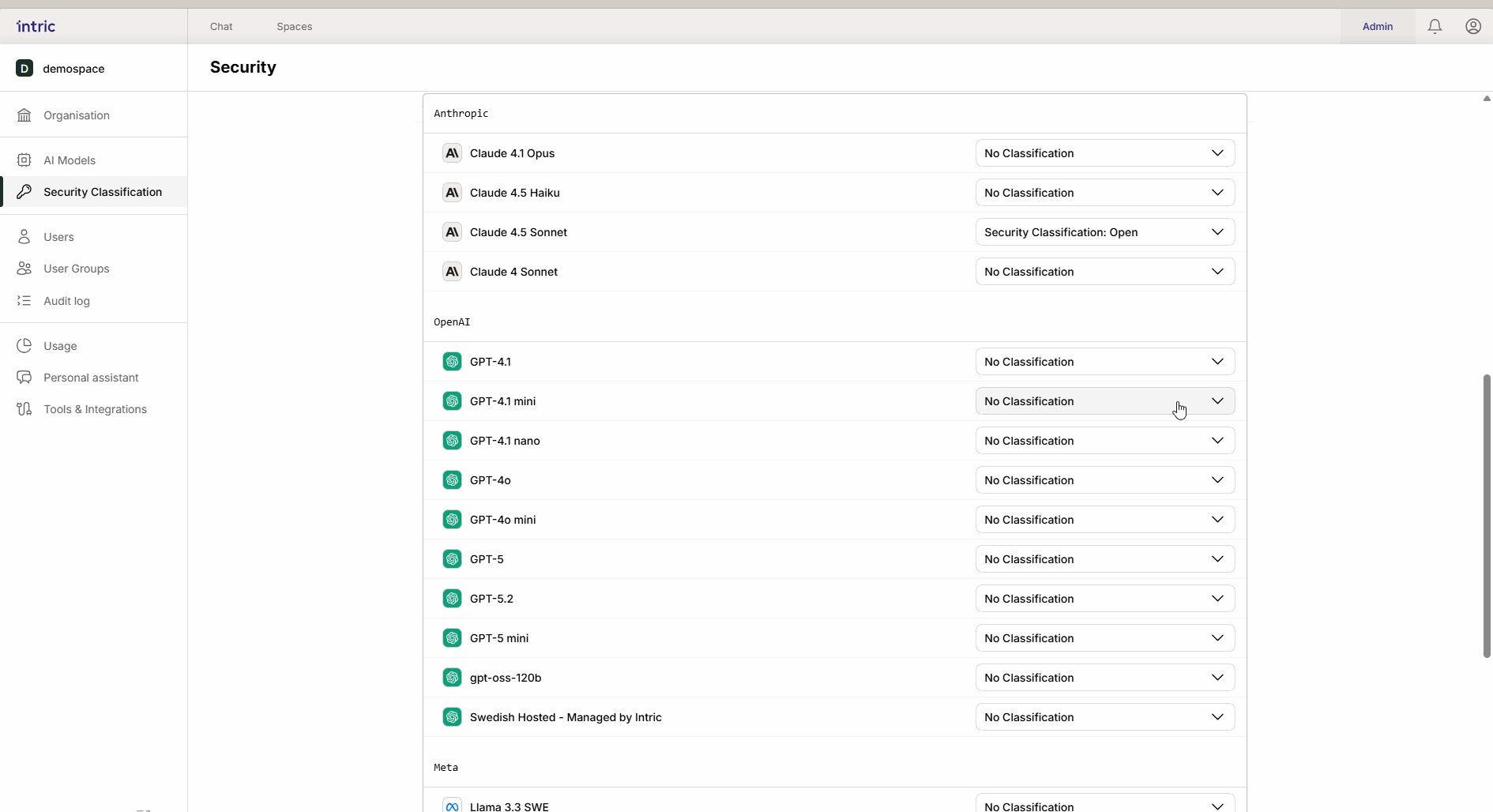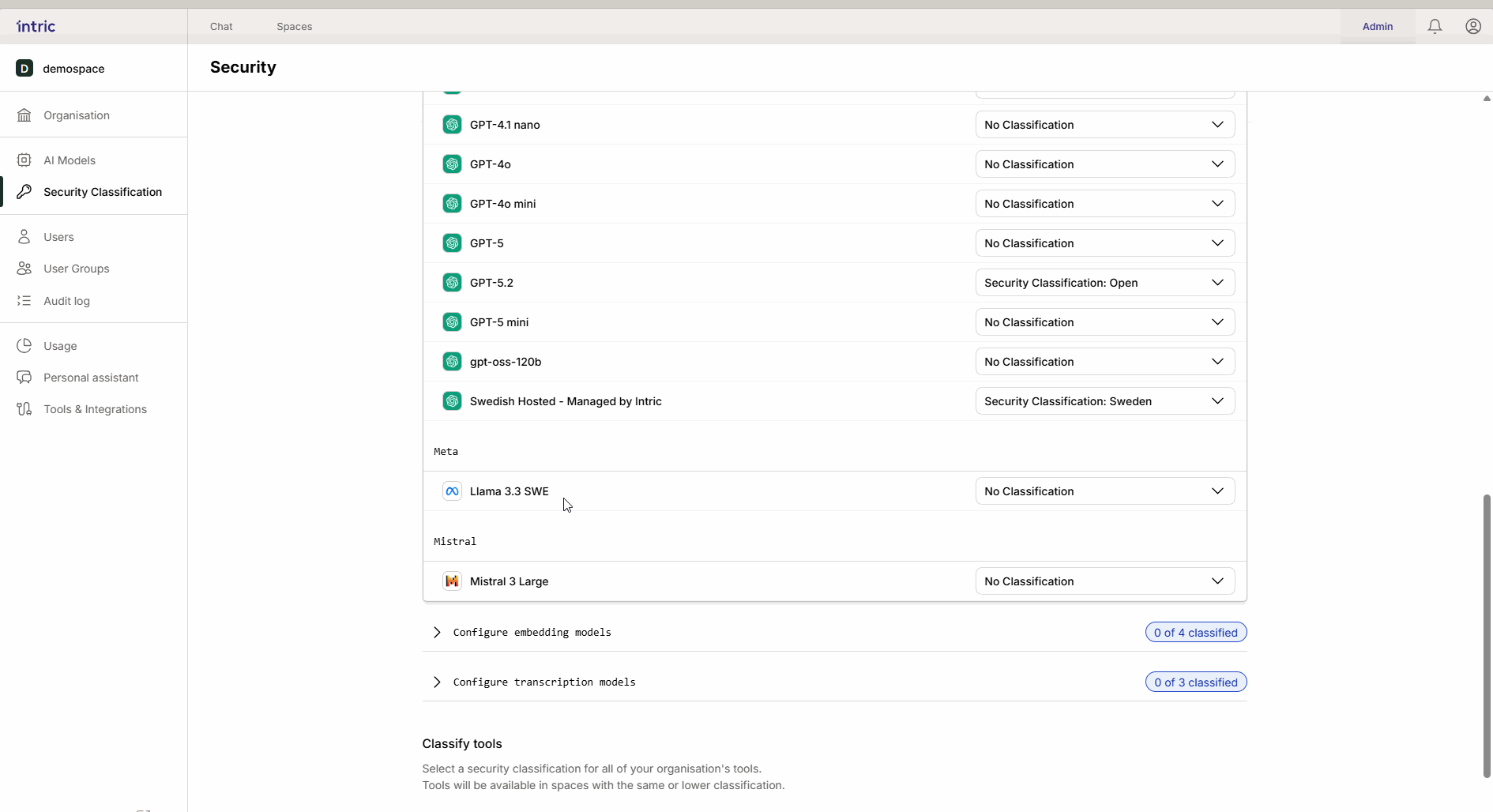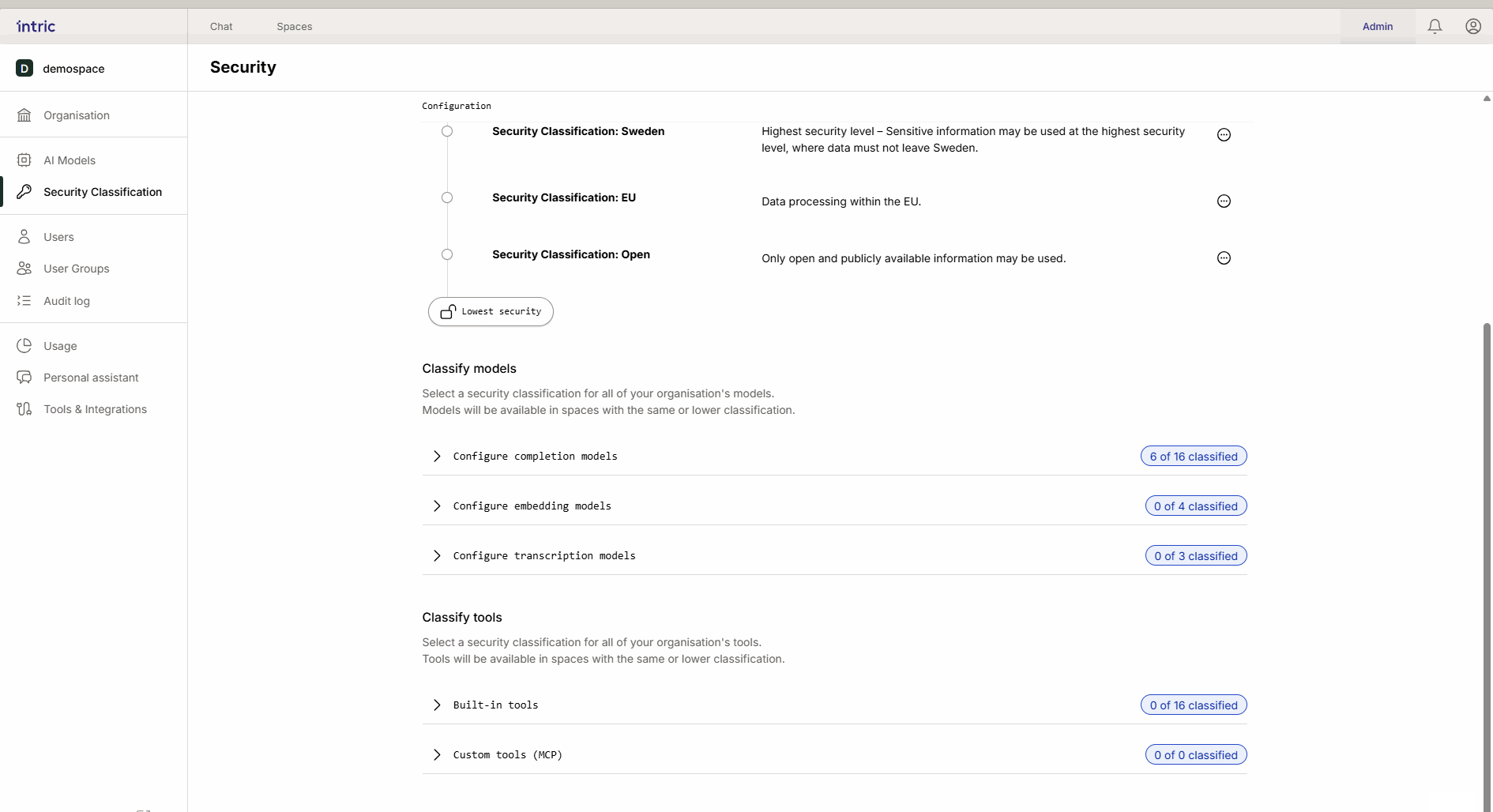
Klassificering av modeller
Olika AI-uppgifter kräver olika typer av modeller. I Intric klassificerar du tre huvudtyper av modeller för att styra var data får behandlas.
1. Språkmodeller (LLM)
Detta är “motorn” i assistenten som skapar text och resonerar. En kraftfull modell som körs i USA (t.ex. GPT-4o) klassificeras ofta lägre (t.ex. Öppen), medan en modell som körs lokalt i Sverige eller EU kan klassificeras högre (Känslig/Sekretess). Tack vare arvet blir den lokala “säkra” modellen även tillgänglig i det öppna spacet om så önskas.
2. Embedding-modeller
Dessa modeller används för att omvandla era dokument (Knowledge) till sökbar data (vektorer).
Viktig regel: Aktivera endast en embedding-modell per säkerhetsklass. Om en användare byter modell i efterhand kan tidigare uppladdad kunskap bli otillgänglig eftersom de olika modellerna “talar olika språk”.
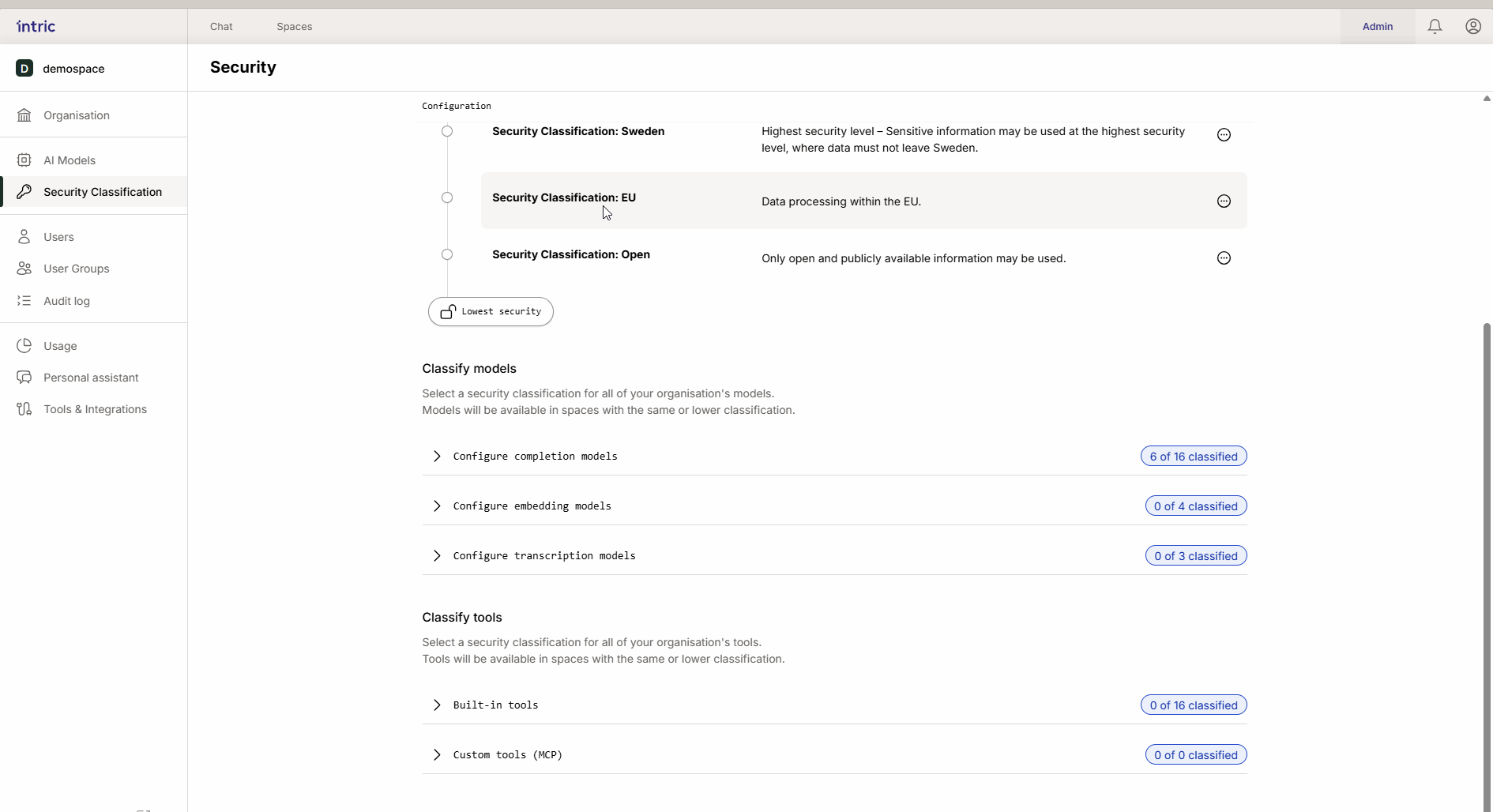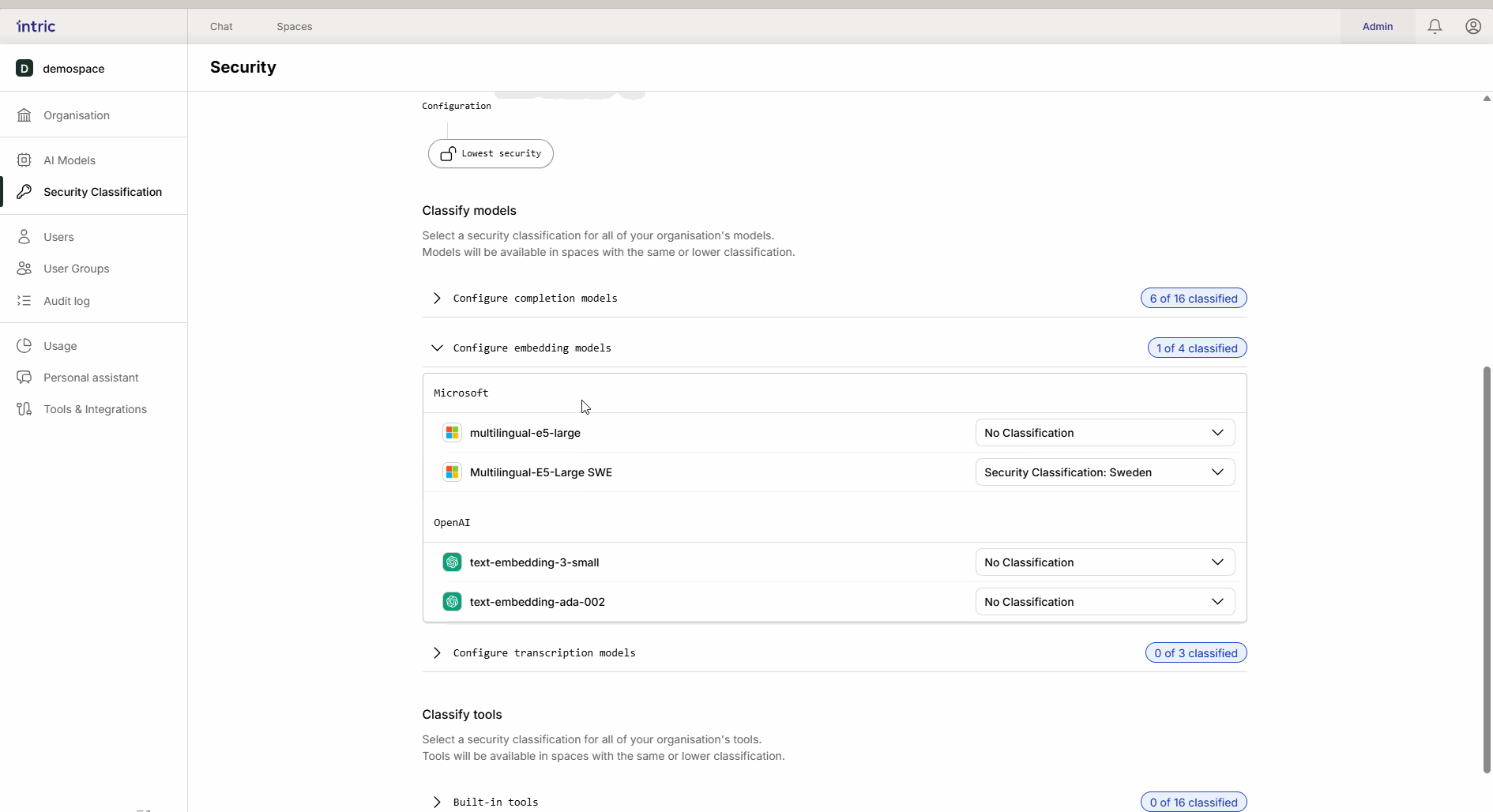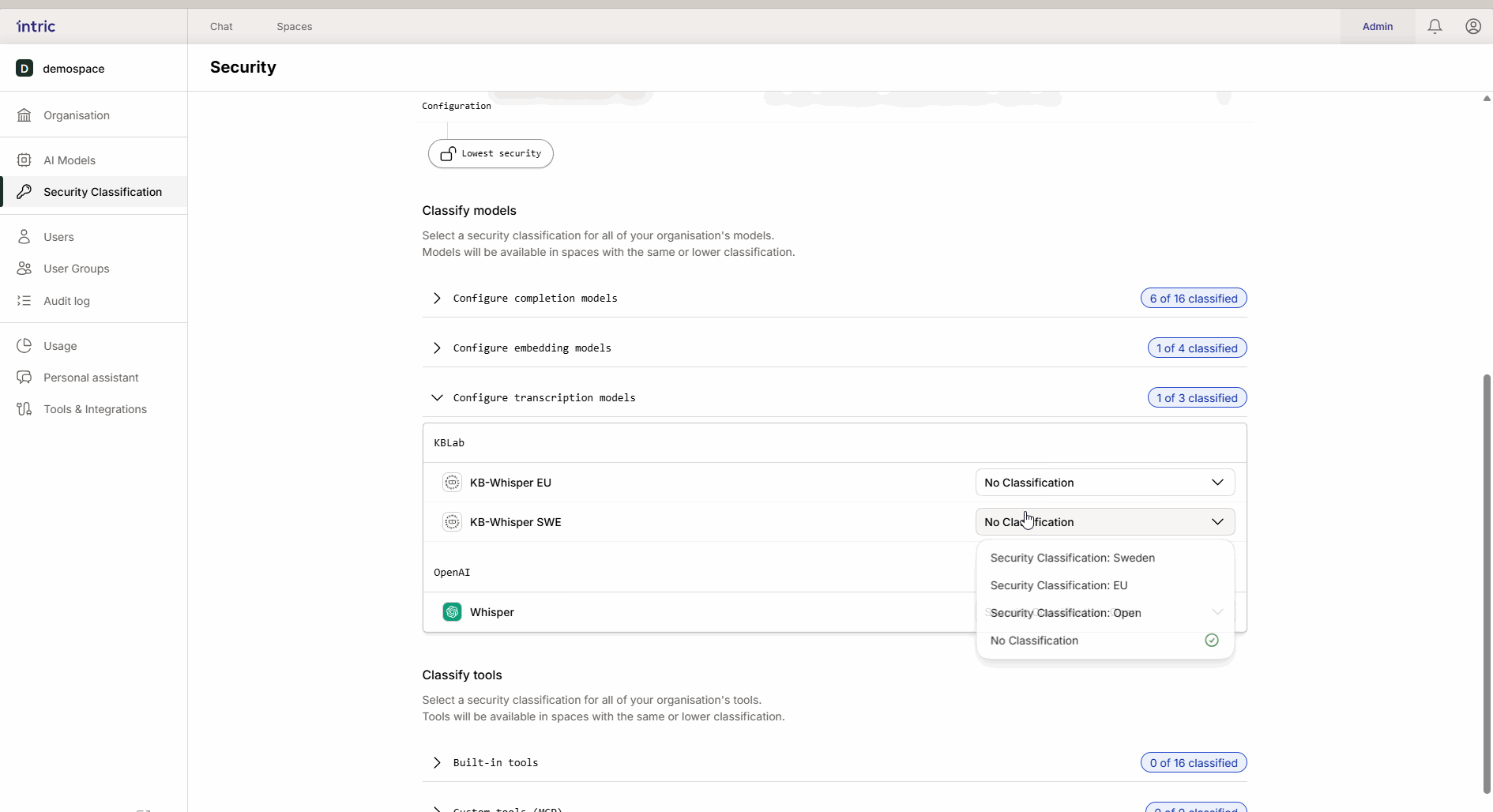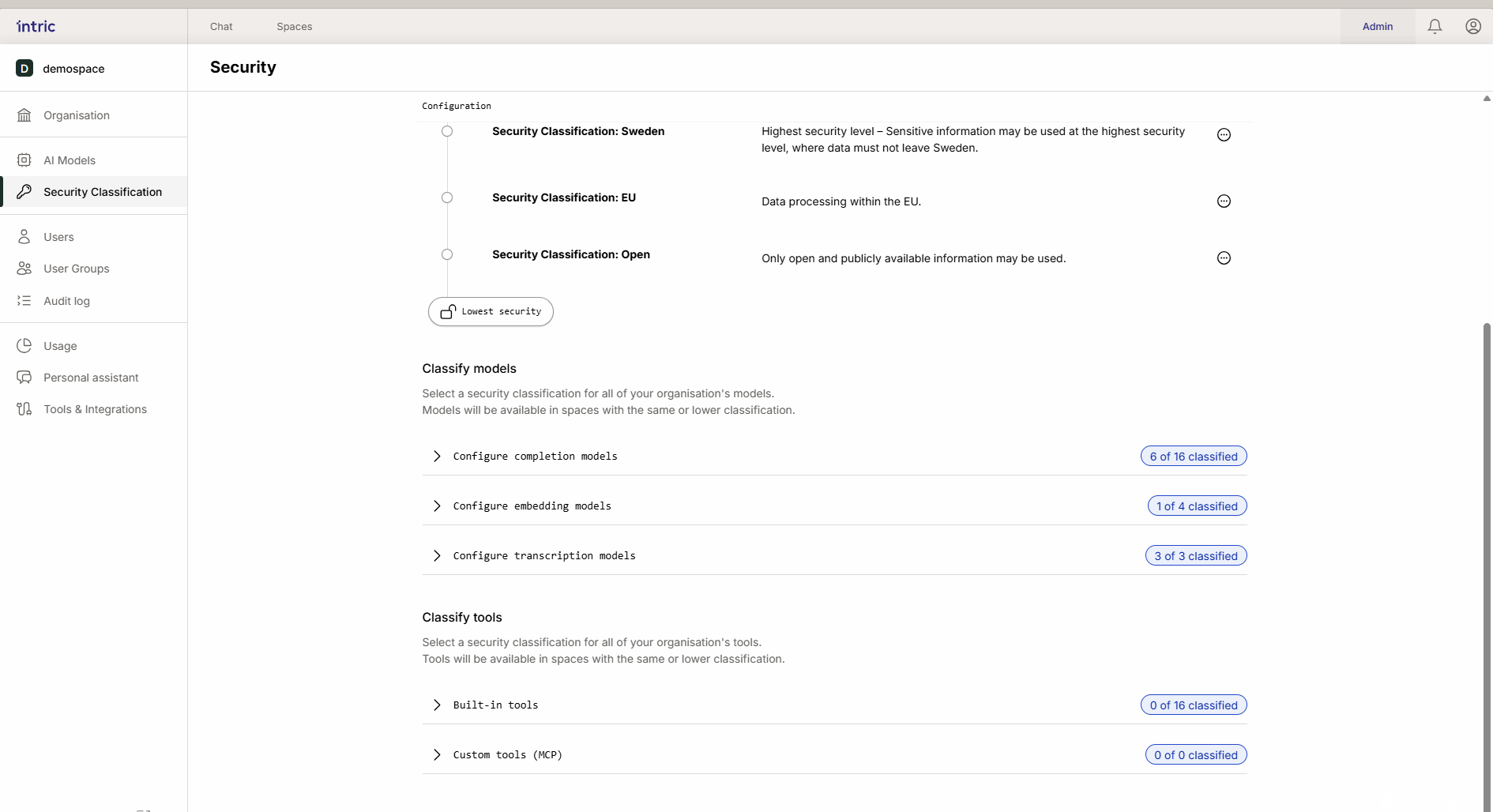
3. Transkriptionsmodeller
Används för att omvandla tal till text (t.ex. när du laddar upp en ljudfil från ett möte). Medan språkmodellen analyserar texten, är det transkriptionsmodellen som först “lyssnar” på filen. Om ett möte innehåller känslig information måste även transkriptionsmodellen vara klassificerad därefter.