Webbplatser
Det är möjligt att ansluta externa hemsidor till Intric för att använda deras information som en del av assistenternas kunskapsbas. Genom att indexera (crawla) en webbplats kan assistenten svara på frågor baserat på specifikt innehåll från er organisation, dokumentationssidor eller publika resurser.
Så här gör du
Logga in i Intric och lokalisera “Webbplatser” i den övre menyn.
Klicka på knappen “Anslut webbplats”.
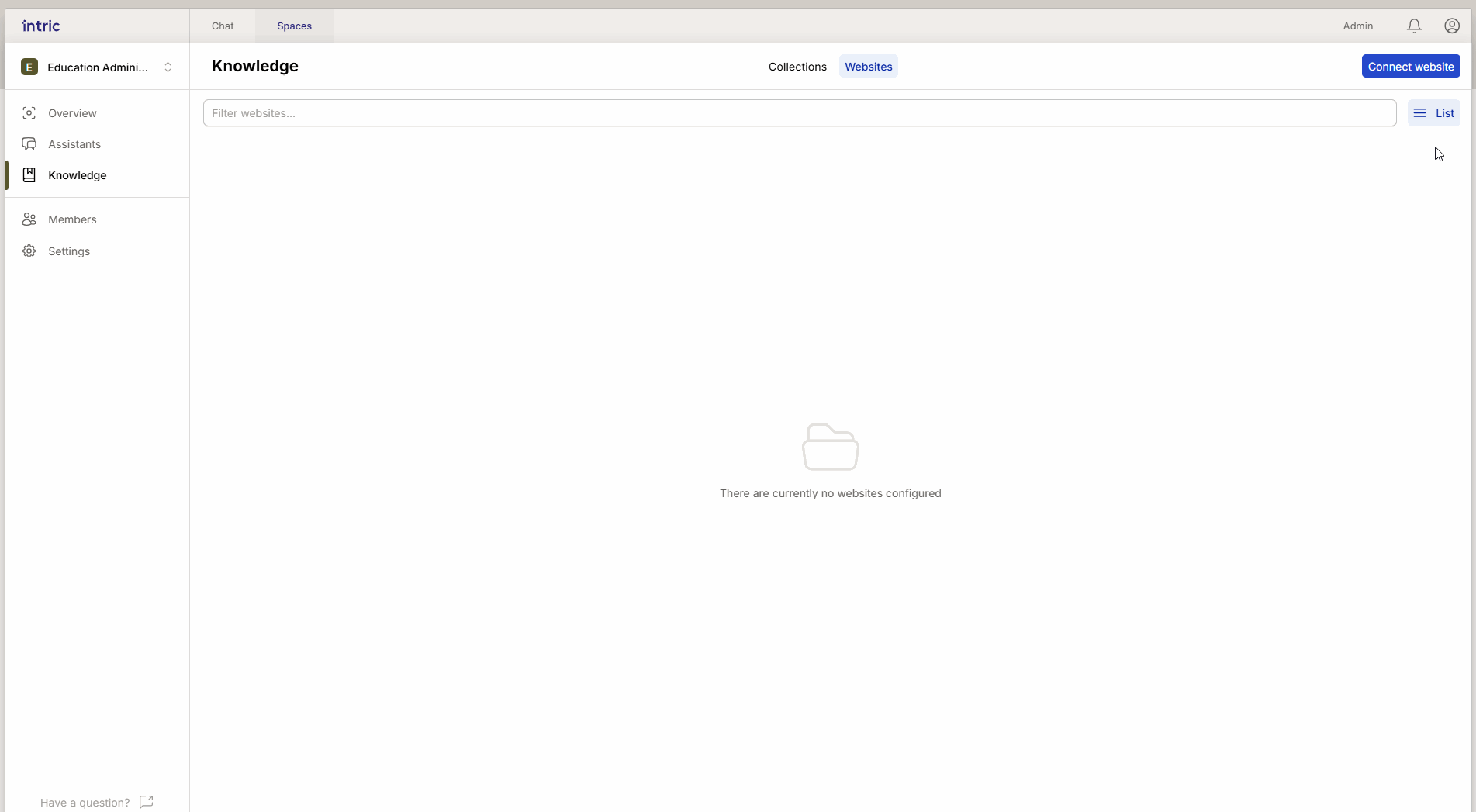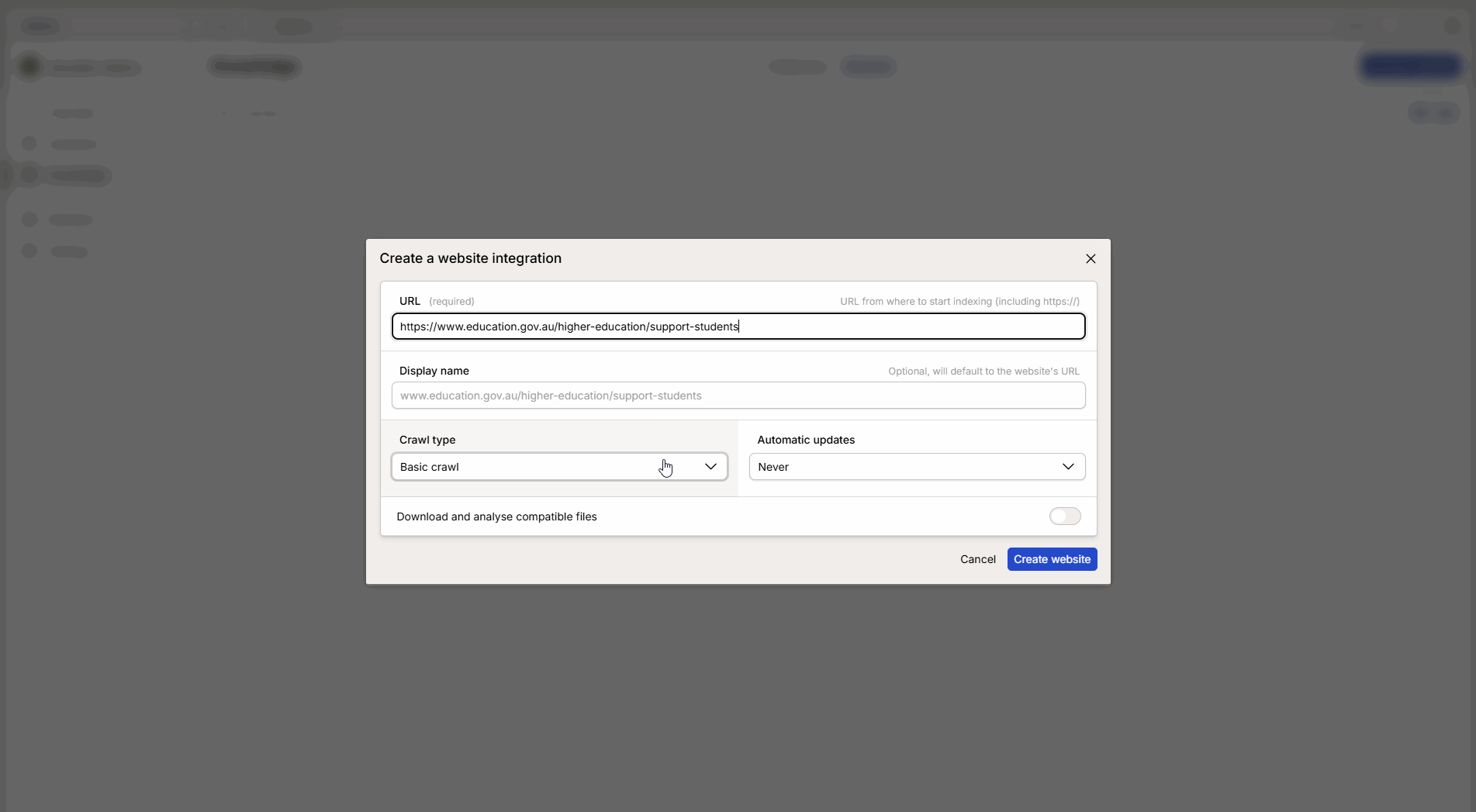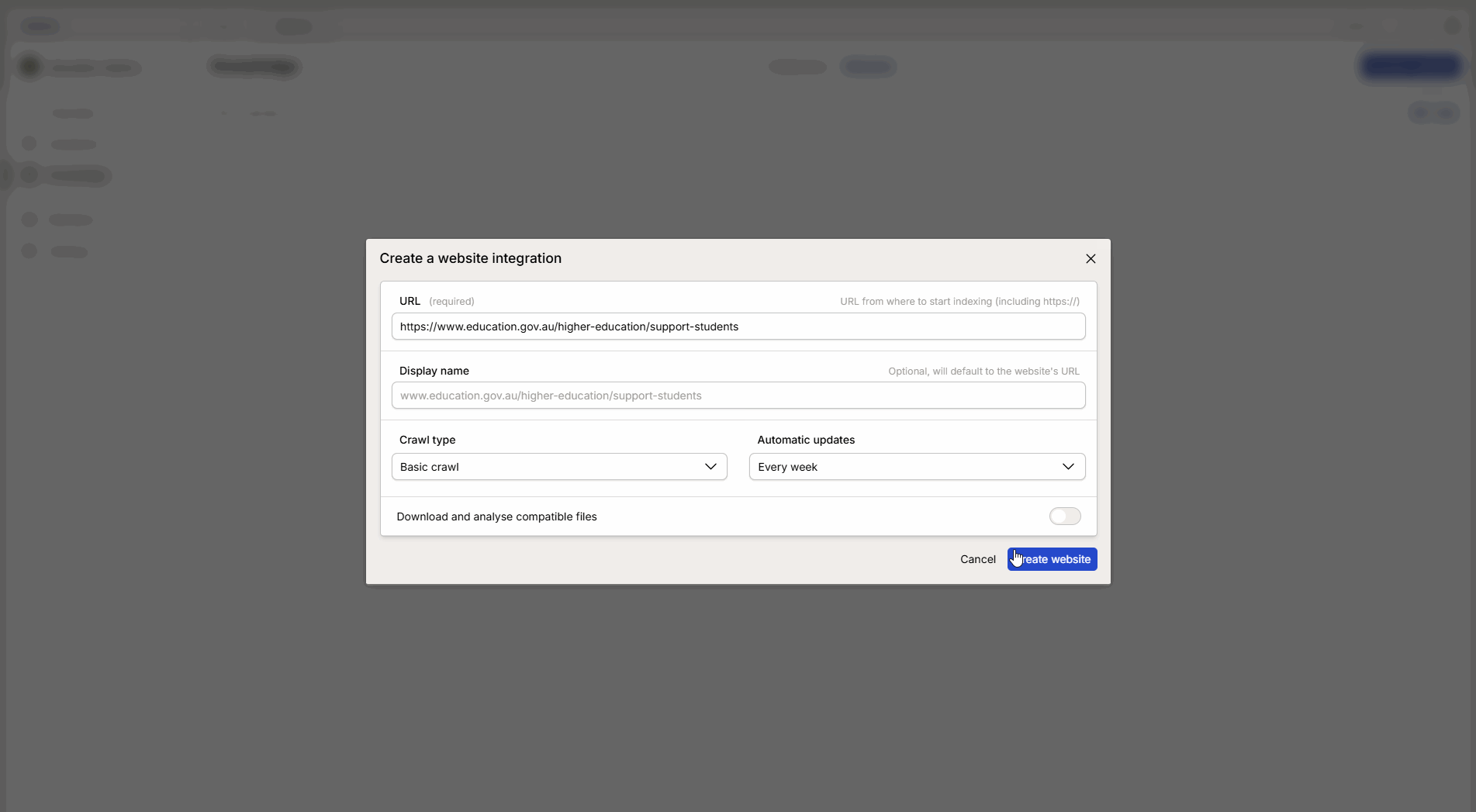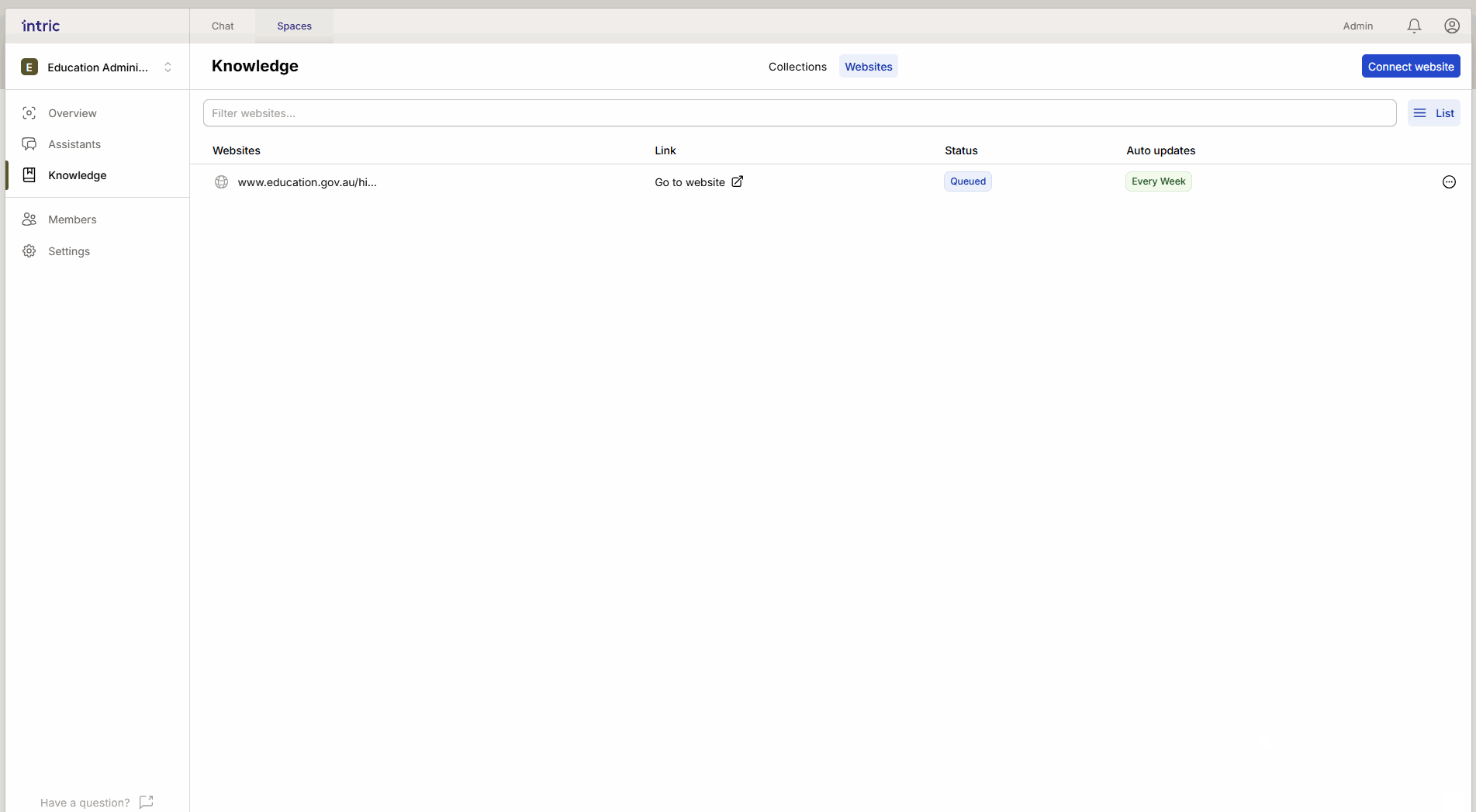
Fyll i uppgifterna i konfigurationsfönstret:
URL: Klistra in länken till den valda hemsidan.
Metod för crawl: Välj den metod som bäst passar syftet (se förklaring nedan).
Textinbäddningsmodell (Embedding): Välj modell.
- Best practice: Aktivera endast en embedding-modell per säkerhetsklass för att undvika att uppladdad kunskap blir otillgänglig vid modellbyte.
Uppdateringsintervall: Välj hur ofta Intric ska hämta ny information från sidan.
Tips: En mer specifik URL ger ofta bättre resultat. Det är mer effektivt att välja en subdomän eller specifik sökväg med relevant information (t.ex.
intric.ai/docs) framför en hel webbplats (intric.ai).
Fördjupning: Metod – Crawling
Crawling innebär att Intric systematiskt läser in sidorna på en webbplats. Det finns två metoder för att styra hur Intric hittar innehållet:
- Basic Crawl: Intric börjar på den angivna URL:en och följer sedan interna länkar för att upptäcka nytt innehåll. Det fungerar ungefär som en mänsklig besökare som klickar sig vidare från sida till sida.
- Sitemap: Intric läser in webbplatsens egen “innehållsförteckning” (en sitemap.xml-fil). Detta är effektivt för mycket stora webbplatser, men kräver att webbplatsen har en korrekt konfigurerad sitemap-fil.
| Metod | Fördelar | Nackdelar |
|---|---|---|
| Basic Crawl | Självgående & Heltäckande: Hittar automatiskt allt innehåll en användare kan se. Kräver ingen teknisk konfiguration av webbplatsen. | Resurskrävande: Tar längre tid att indexera en hel sida och det finns en risk att ovidkommande sidor crawlas om man inte begränsar djupet. |
| Sitemap | Snabb & Exakt: Du har full kontroll över exakt vilka sidor som indexeras via en xml-fil. Mycket effektivt för stora webbplatser. | Tekniskt beroende: Kräver att webbplatsen har en korrekt uppdaterad sitemap-fil. Hittar inget som saknas i listan. |
Rekommendation: Vår rekommendation är att i de allra flesta fallen använda “basic crawl”. Det kräver ingen teknisk förberedelse av webbplatsen och säkerställer att assistenten hittar allt innehåll som är synligt för en vanlig användare.