Nettsteder
Det er mulig å koble eksterne nettsteder til Intric for å bruke informasjonen deres som en del av assistentenes kunnskapsbase. Ved å indeksere (crawle) et nettsted kan assistenten svare på spørsmål basert på spesifikt innhold fra organisasjonen din, dokumentasjonssider eller offentlige ressurser.
Slik gjør du det
Logg inn på Intric og finn “Nettsteder” i toppmenyen.
Klikk “Koble nettsted”-knappen.
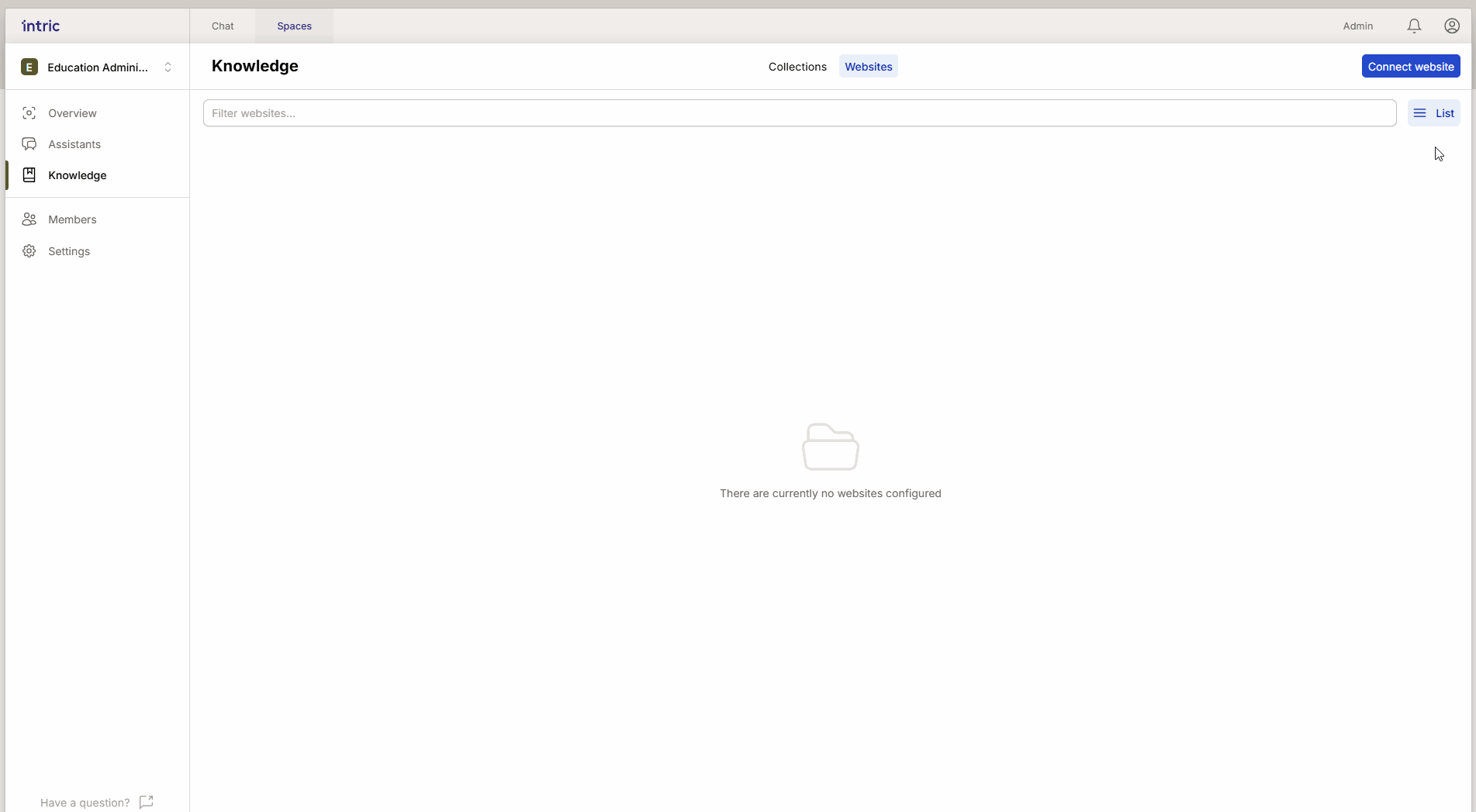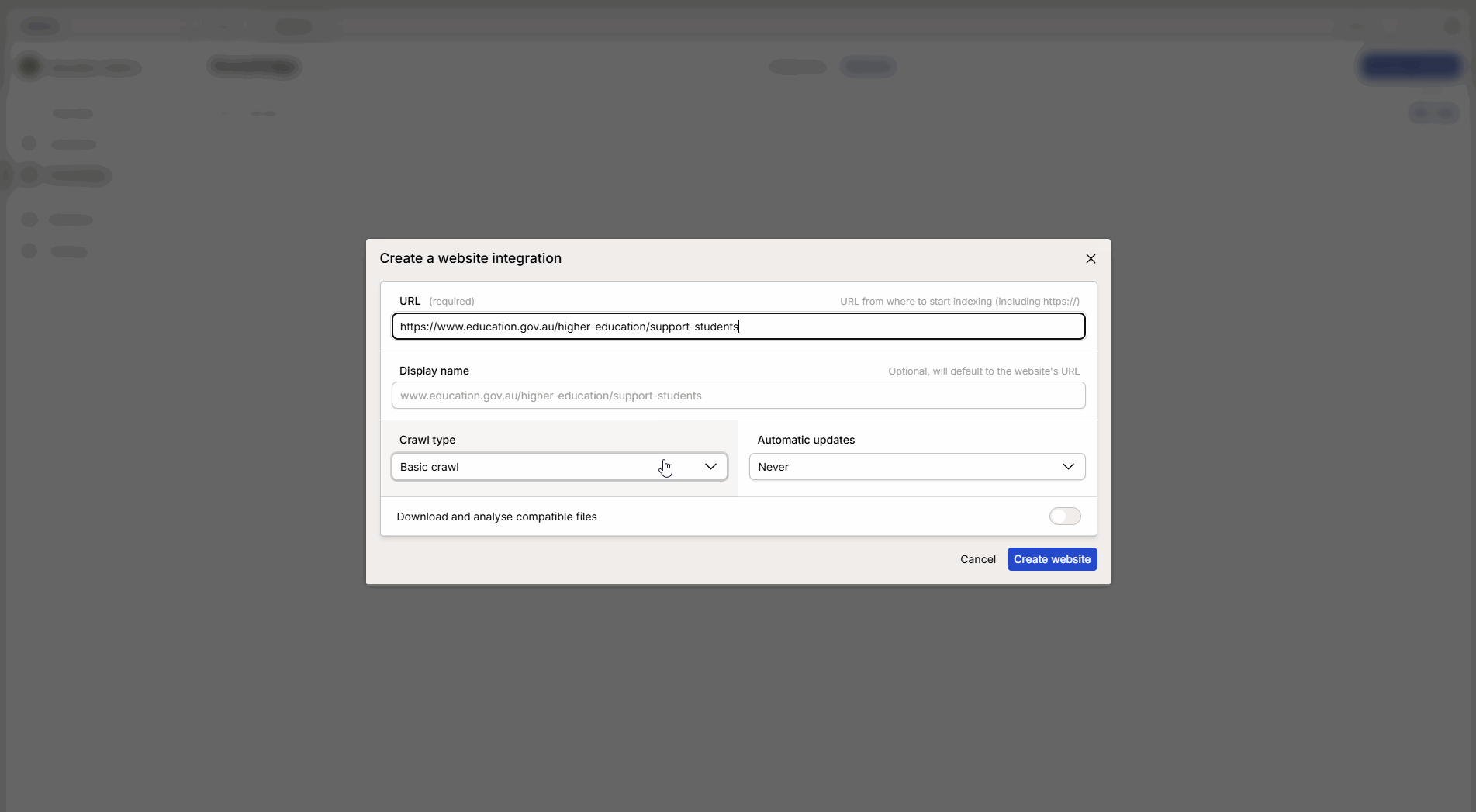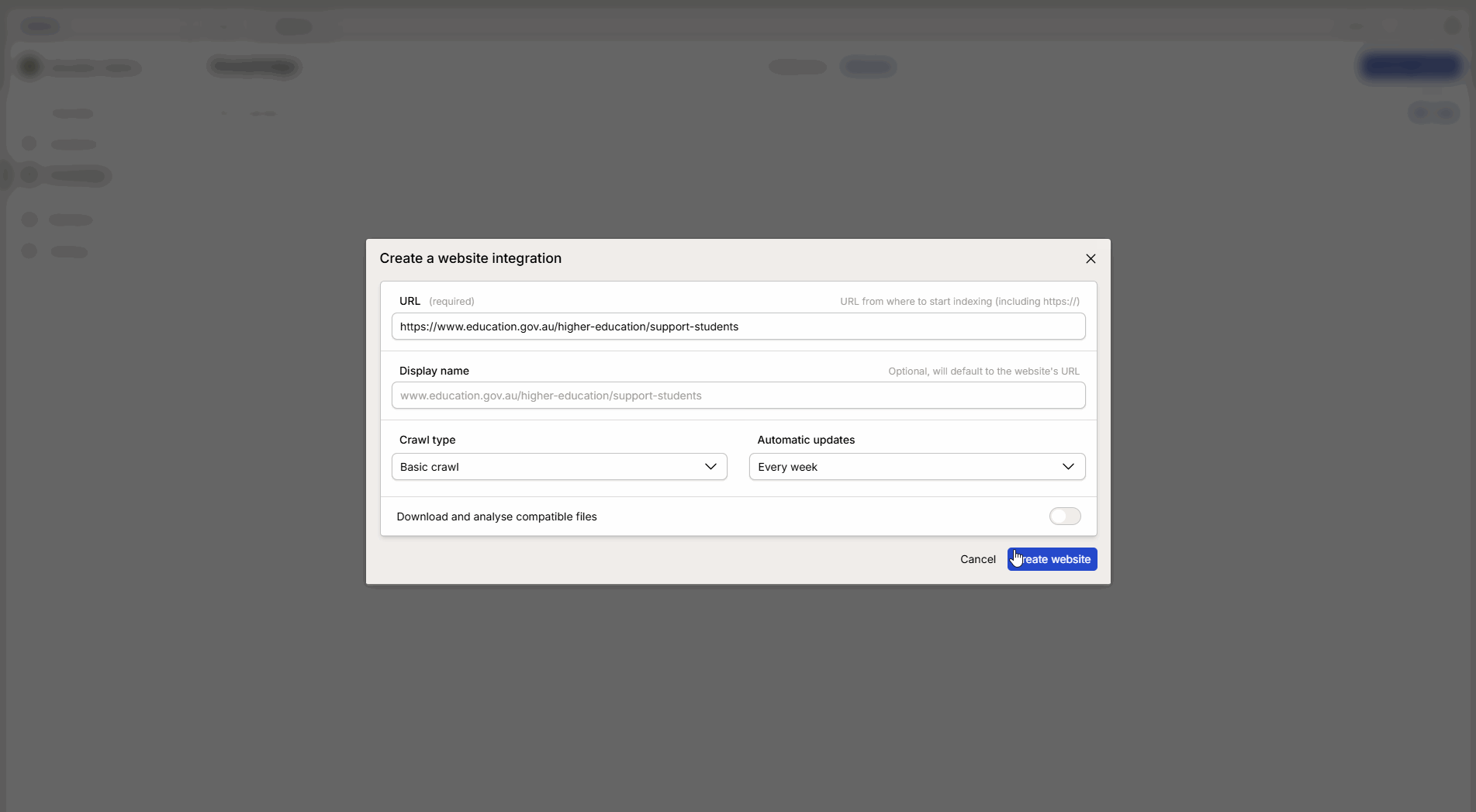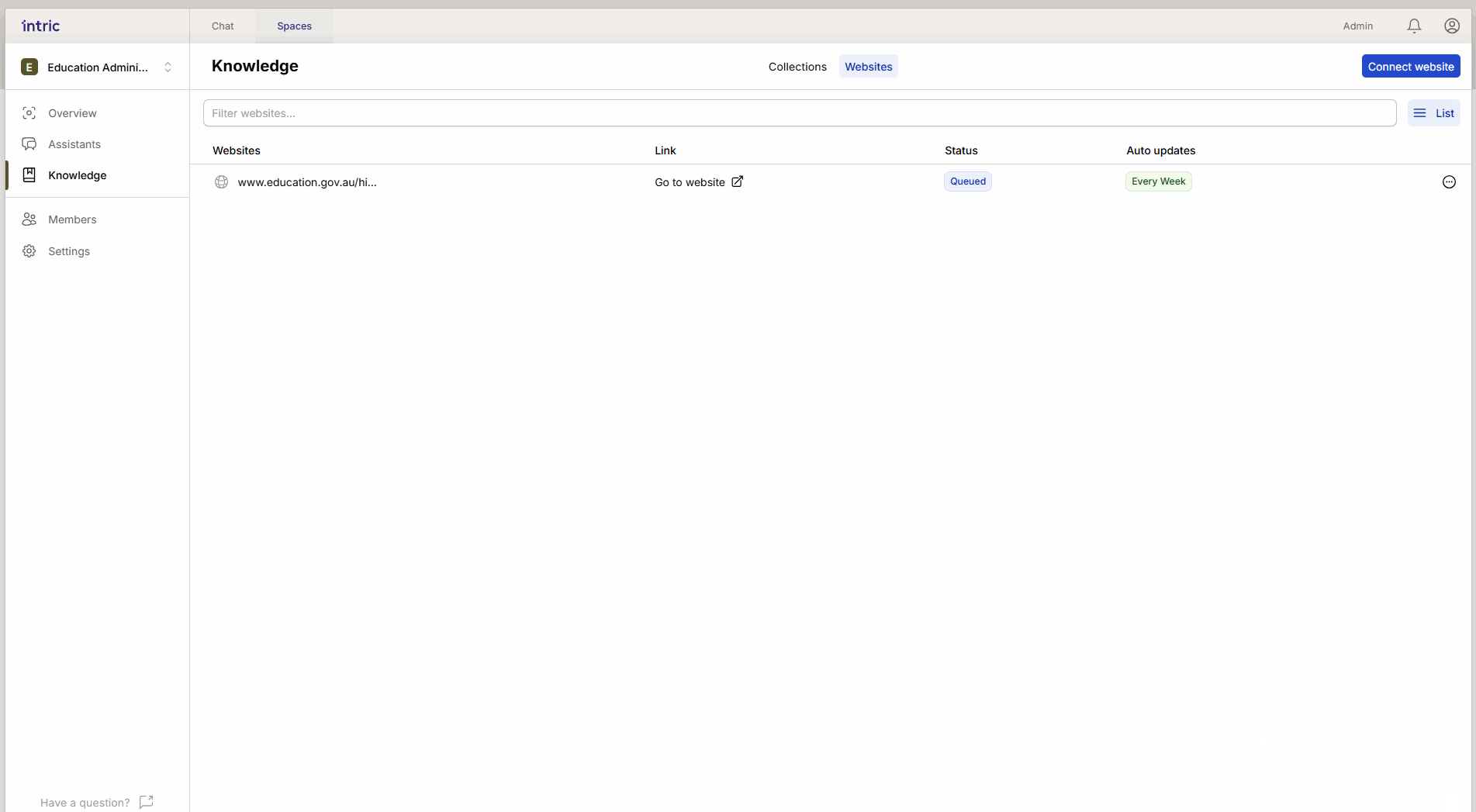
Fyll ut informasjonen i konfigurasjonsvinduet:
URL: Lim inn lenken til det valgte nettstedet.
Crawl-metode: Velg metoden som passer best til formålet (se forklaring nedenfor).
Tekstembedding-modell (Embedding): Velg modell.
- Best practice: Aktiver bare én embedding-modell per sikkerhetsklasse for å unngå at opplastet kunnskap blir utilgjengelig ved modellbytte.
Oppdateringsintervall: Velg hvor ofte Intric skal hente ny informasjon fra siden.
Tips: En mer spesifikk URL gir ofte bedre resultater. Det er mer effektivt å velge et underdomene eller spesifikk bane med relevant informasjon (f.eks.
intric.ai/docs) i stedet for en hel nettsted (intric.ai).
Dykk ned: Metode – Crawling
Crawling betyr at Intric systematisk leser sidene på et nettsted. Det er to metoder for å kontrollere hvordan Intric finner innhold:
- Grunnleggende crawl: Intric starter på den spesifiserte URL-en og følger deretter interne lenker for å oppdage nytt innhold. Det fungerer omtrent som en menneskelig besøkende som klikker fra side til side.
- Sitemap: Intric leser nettstedets egen “innholdsfortegnelse” (en sitemap.xml-fil). Dette er effektivt for svært store nettsteder, men krever at nettstedet har en riktig konfigurert sitemap-fil.
| Metode | Fordeler | Ulemper |
|---|---|---|
| Grunnleggende crawl | Selvstendig og omfattende: Finner automatisk alt innhold en bruker kan se. Krever ingen teknisk konfigurasjon av nettstedet. | Ressurskrevende: Tar lengre tid å indeksere en hel side og det er risiko for at irrelevante sider crawles hvis du ikke begrenser dybden. |
| Sitemap | Rask og nøyaktig: Du har full kontroll over nøyaktig hvilke sider som indekseres via en xml-fil. Svært effektivt for store nettsteder. | Teknisk avhengighet: Krever at nettstedet har en riktig oppdatert sitemap-fil. Finner ingenting som mangler fra listen. |
Anbefaling: I de aller fleste tilfeller, bruk “grunnleggende crawl”. Det krever ingen teknisk forberedelse av nettstedet og sikrer at assistenten finner alt innhold som er synlig for en vanlig bruker.