Modellklassifisering
Forskjellige AI-oppgaver krever forskjellige typer modeller. I Intric klassifiserer du tre hovedtyper modeller for å kontrollere hvor data kan behandles.
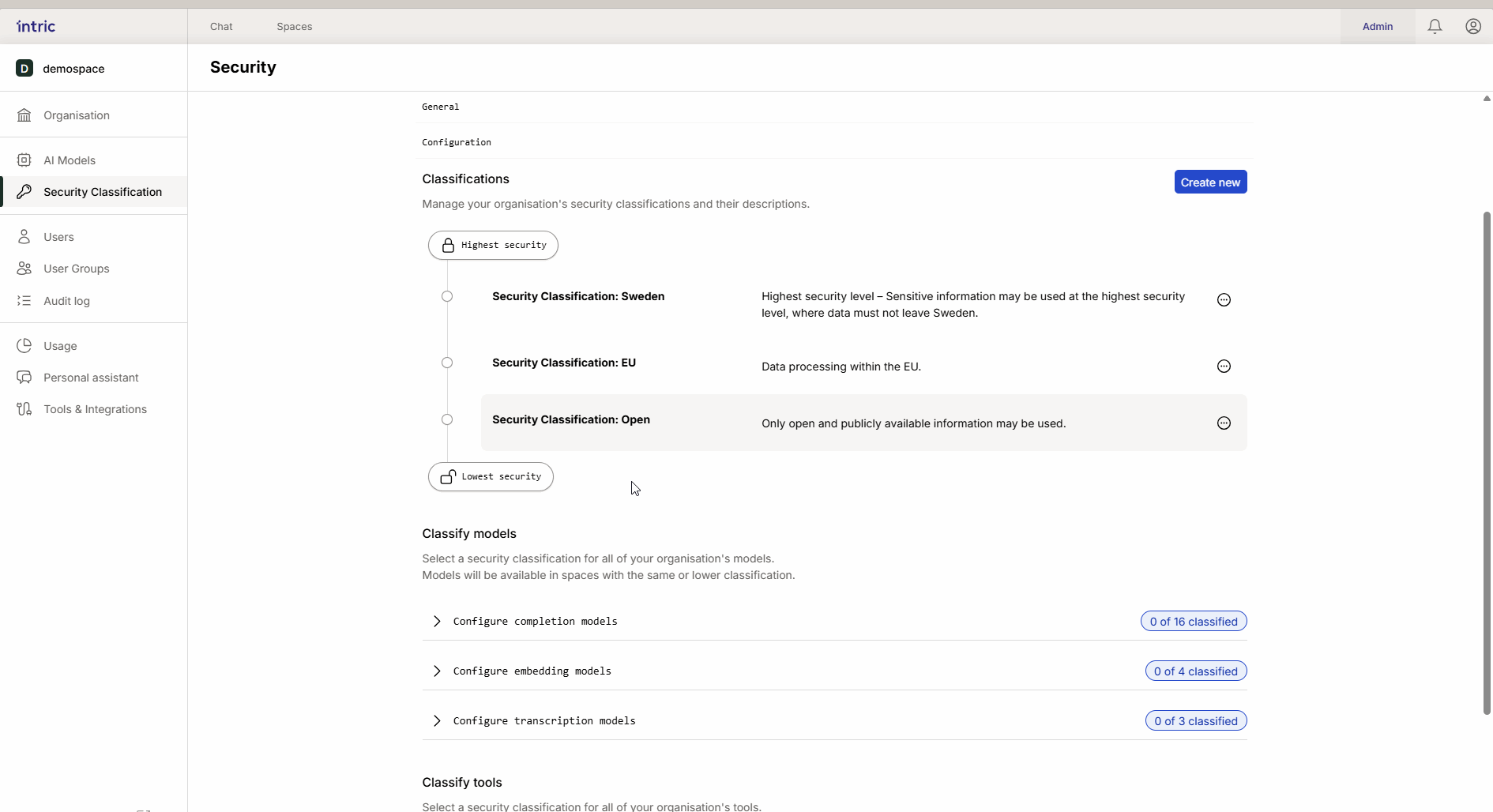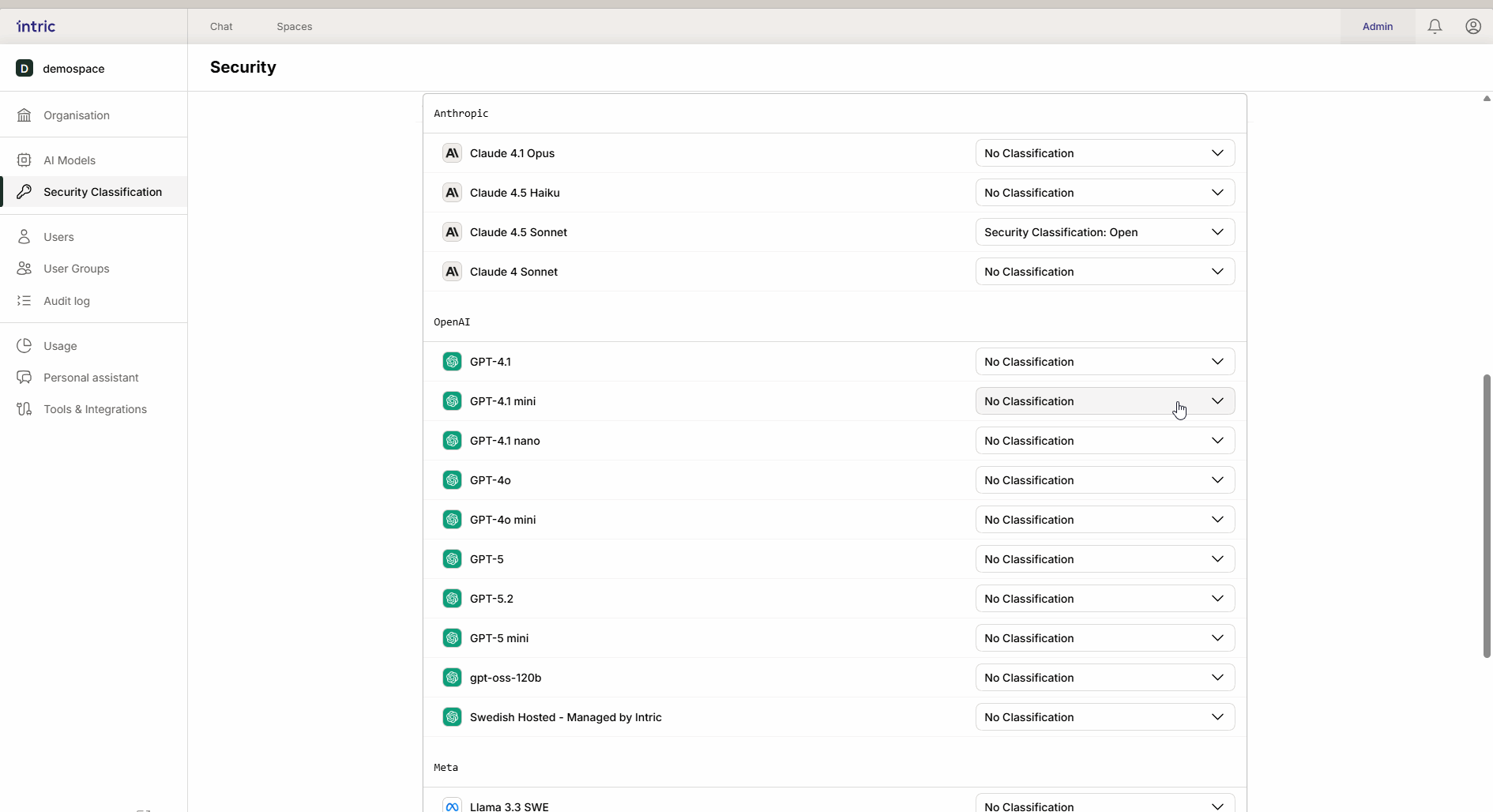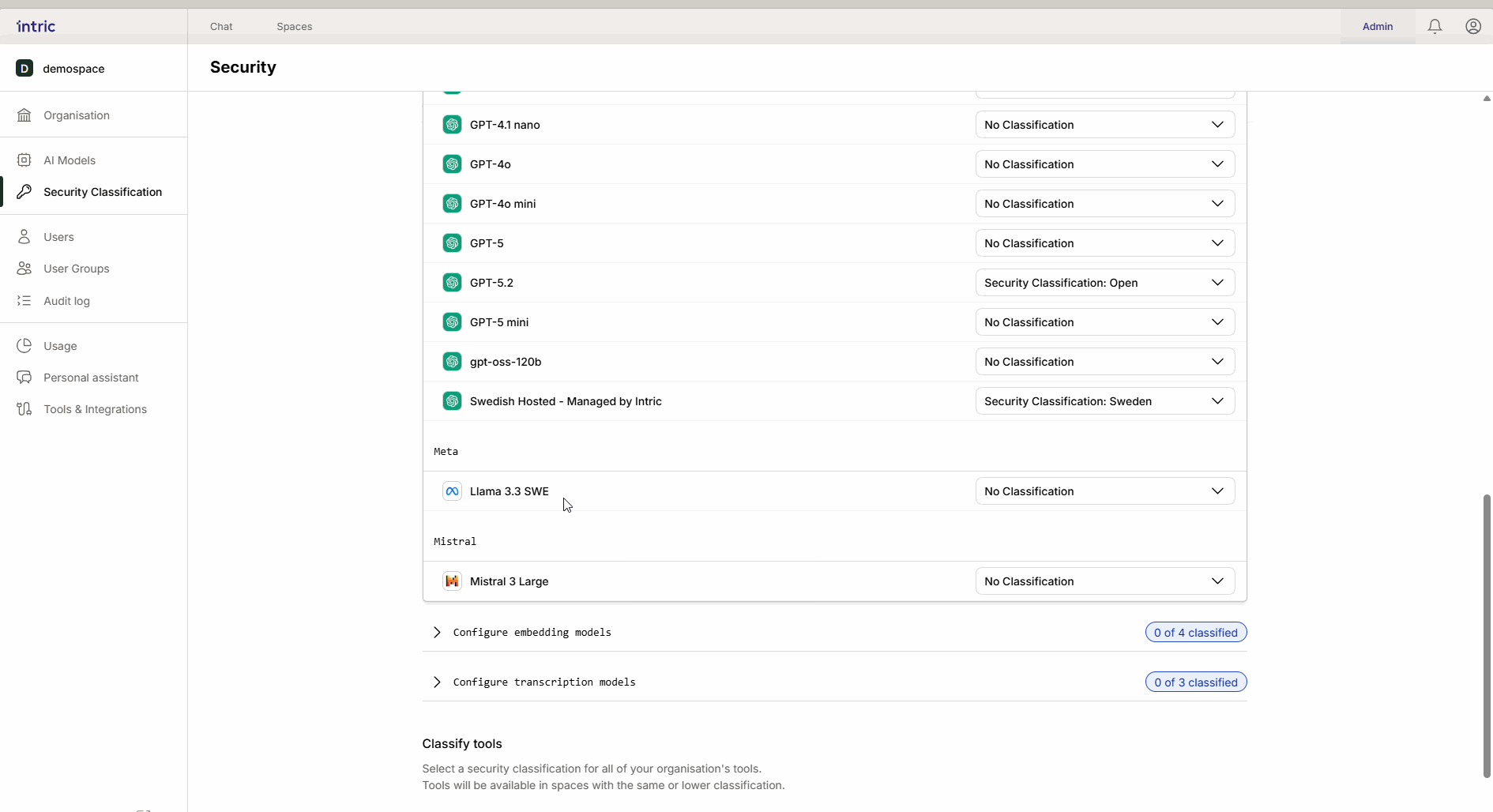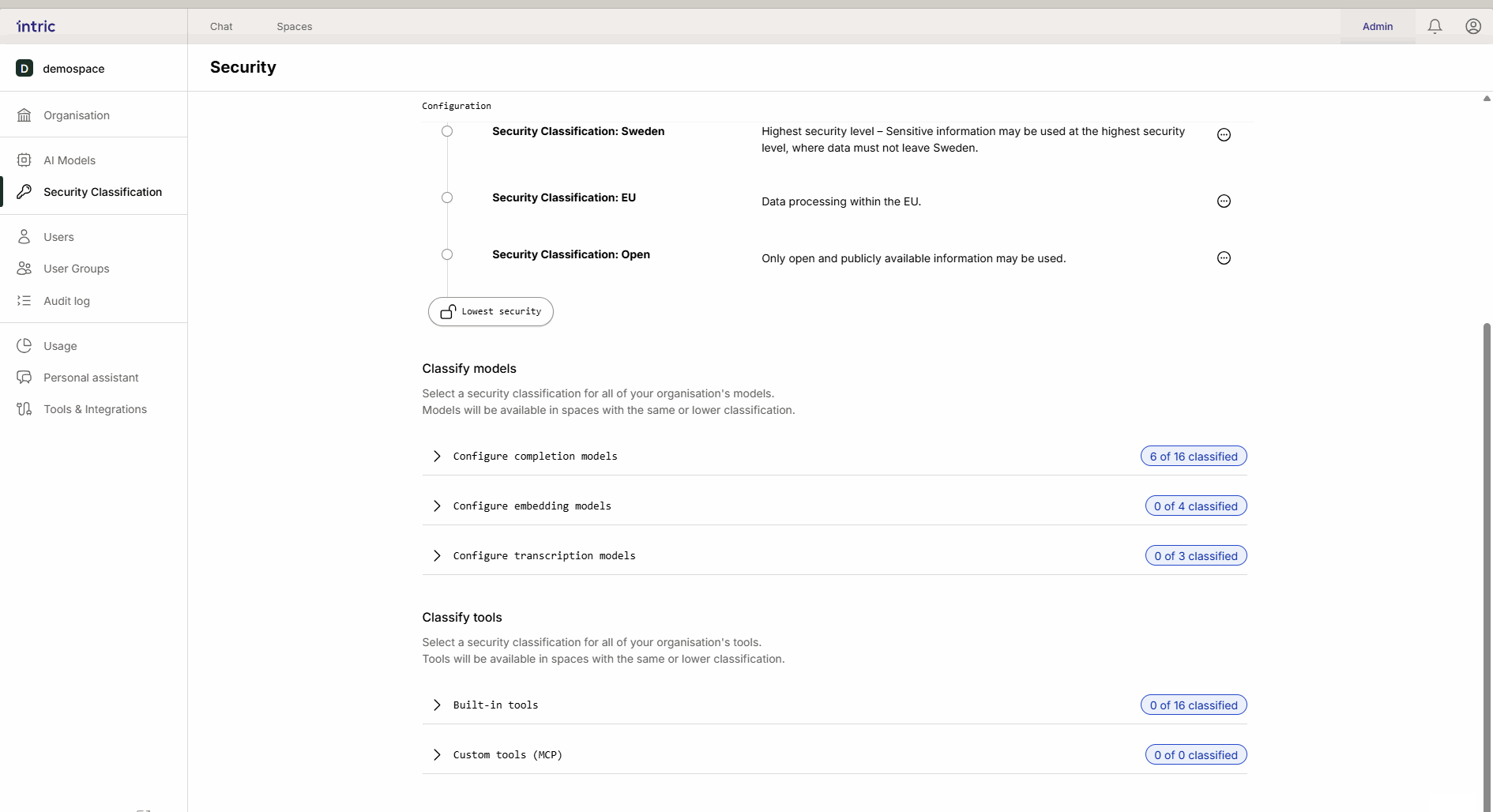
1. Språkmodeller (LLM)
Dette er “motoren” i assistenten som skaper tekst og resonnerer. En kraftig modell som kjører i USA (f.eks. GPT-4o) klassifiseres ofte lavere (f.eks. Åpen), mens en modell som kjører lokalt i Sverige eller EU kan klassifiseres høyere (Sensitiv/Konfidensiell). Takket være arv blir den lokale “sikre” modellen også tilgjengelig i det åpne området hvis ønskelig.
2. Embedding-modeller
Disse modellene brukes til å konvertere dokumentene dine (Kunnskap) til søkbare data (vektorer).
Viktig regel: Aktiver bare én embedding-modell per sikkerhetsklasse. Hvis en bruker bytter modell etterpå, kan tidligere opplastet kunnskap bli utilgjengelig fordi de forskjellige modellene “snakker forskjellige språk.”
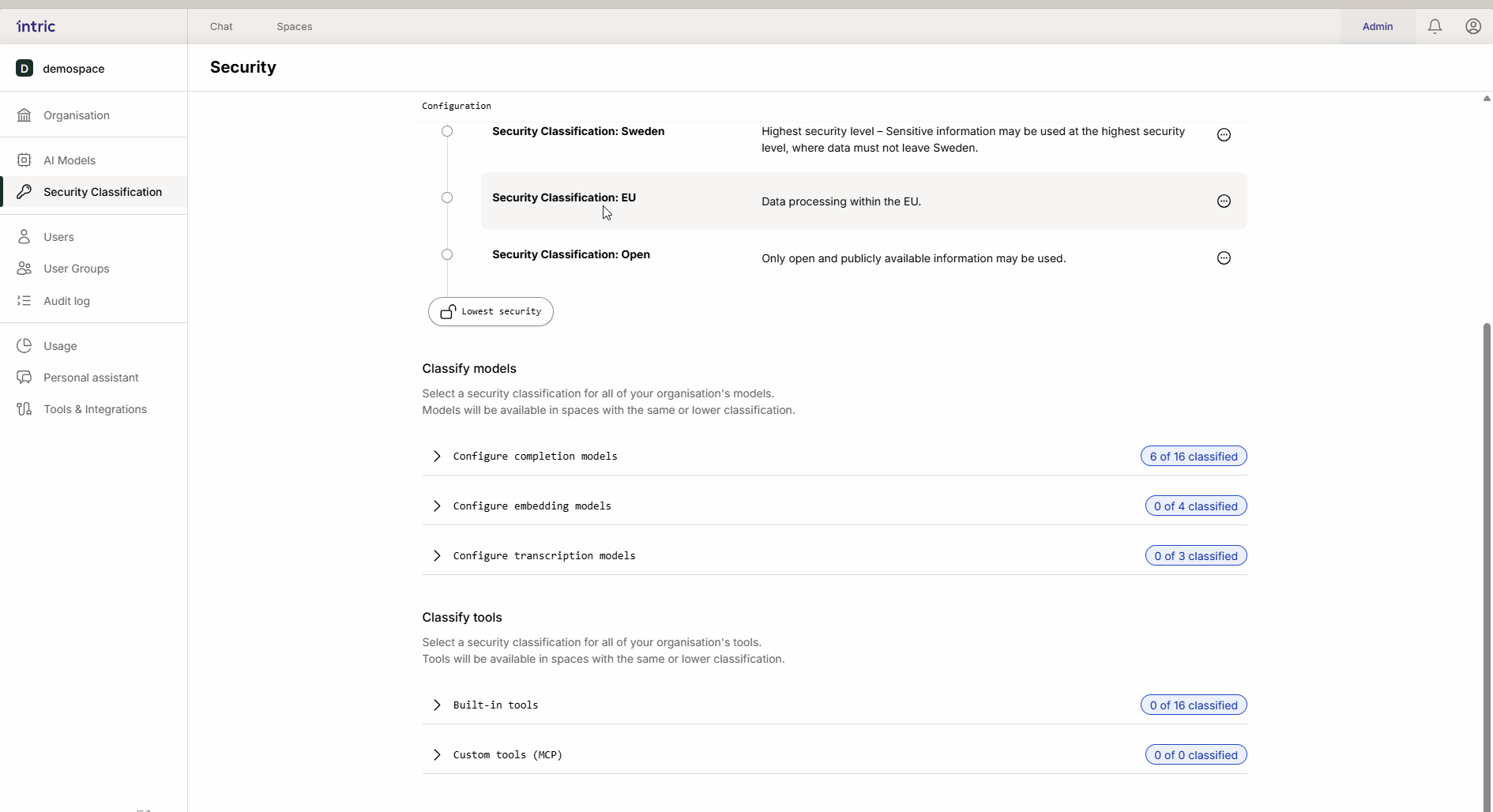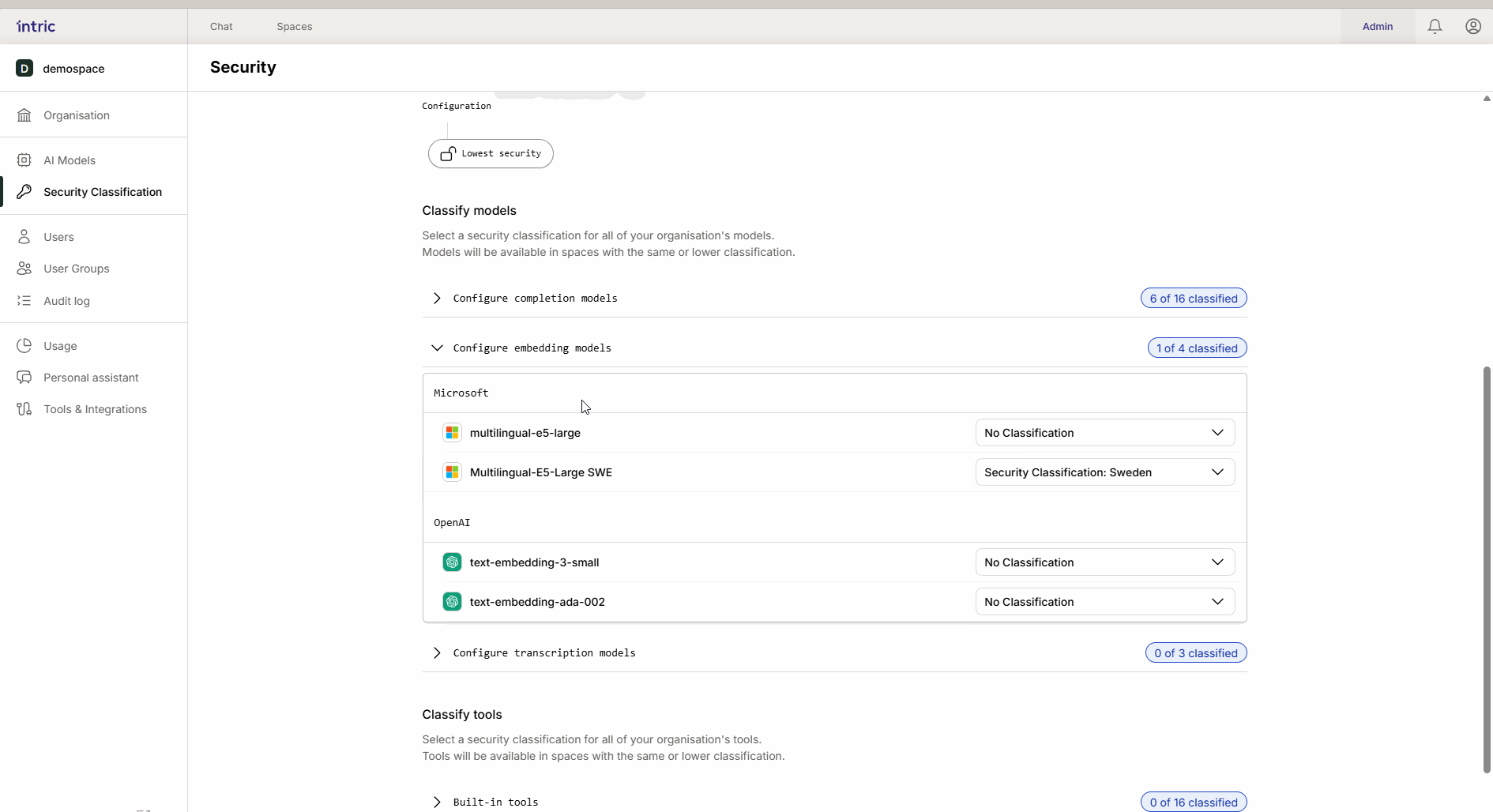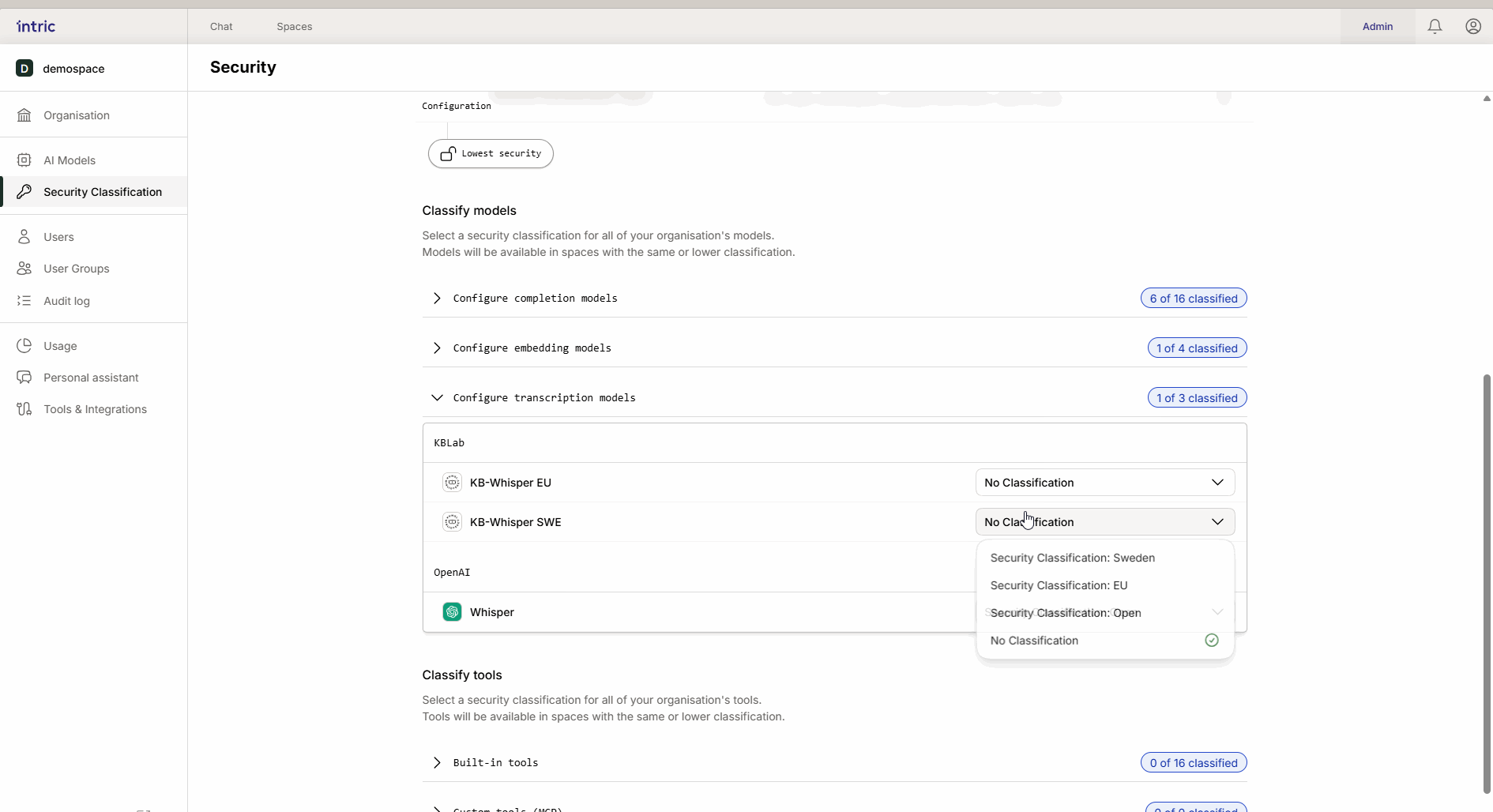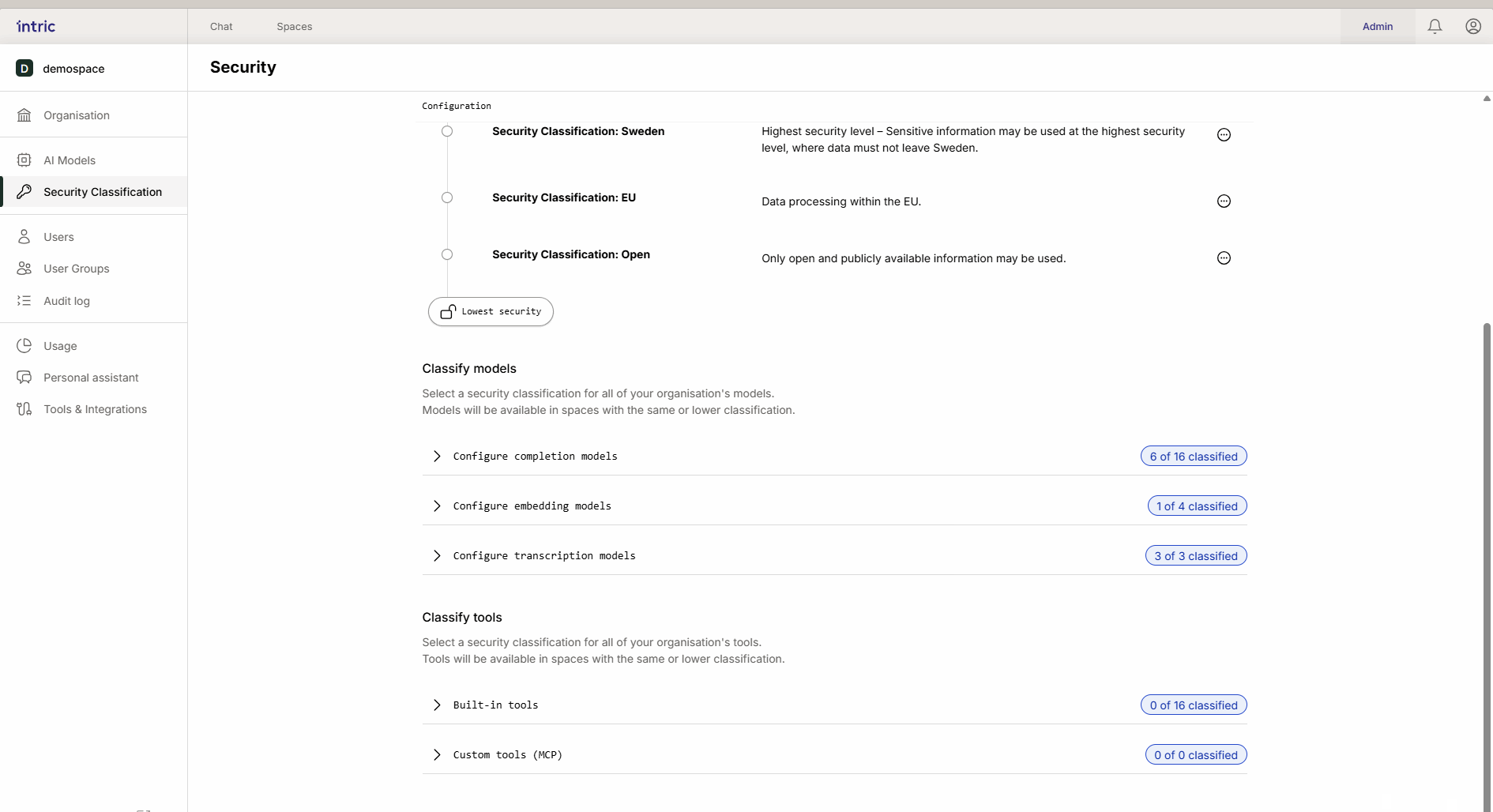
3. Transkripsjonsmodeller
Brukes til å konvertere tale til tekst (f.eks. når du laster opp en lydfil fra et møte). Mens språkmodellen analyserer teksten, er det transkripsjonsmodellen som først “lytter” til filen. Hvis et møte inneholder sensitiv informasjon, må transkripsjonsmodellen også klassifiseres tilsvarende.