Siti web
È possibile collegare siti web esterni a Intric per usare le loro informazioni come parte della base di conoscenza degli assistenti. Indicizzando (crawling) un sito web, l’assistente può rispondere a domande basate su contenuti specifici dalla tua organizzazione, pagine di documentazione o risorse pubbliche.
Come farlo
Accedi a Intric e localizza “Siti web” nel menu in alto.
Clicca il pulsante “Collega sito web”.
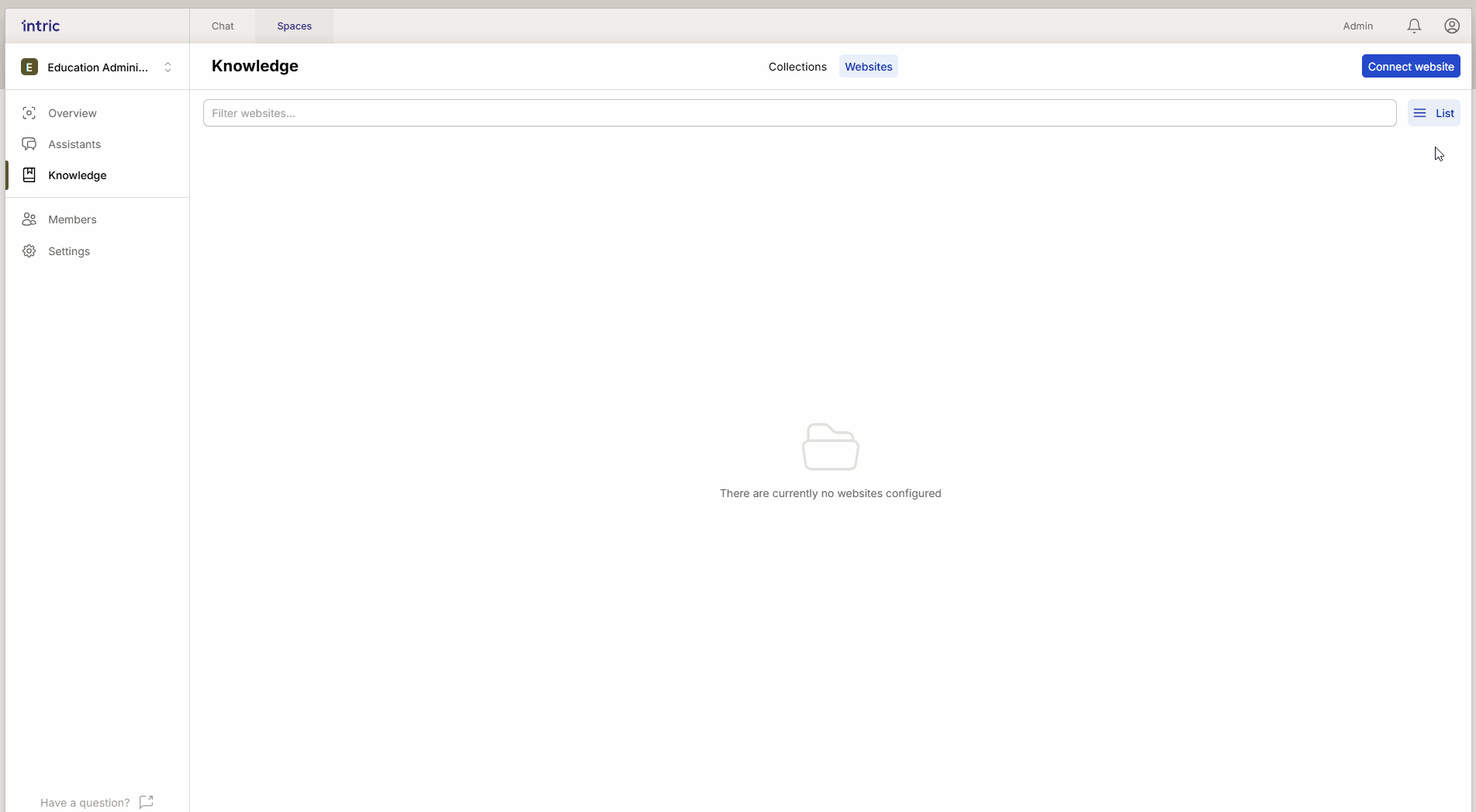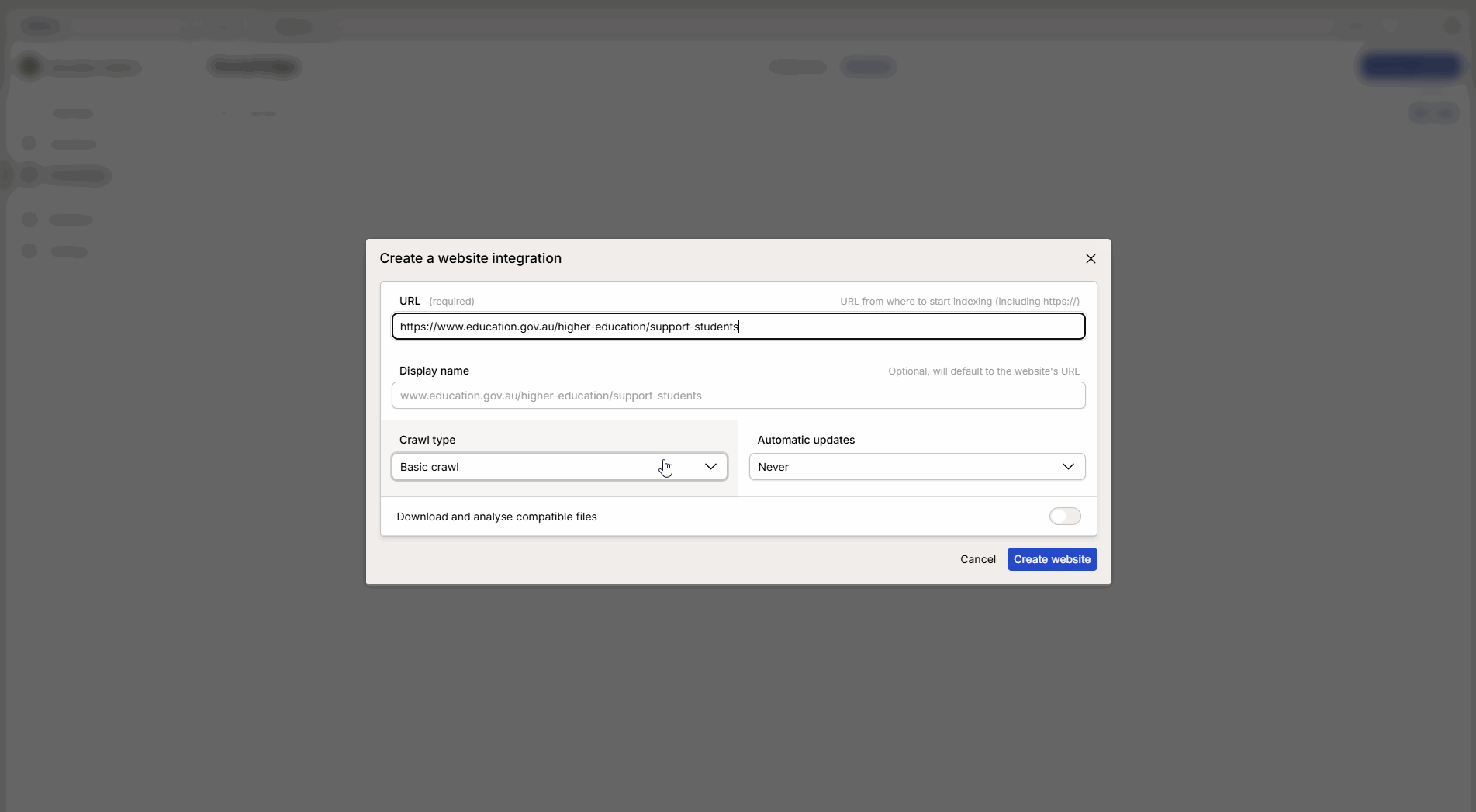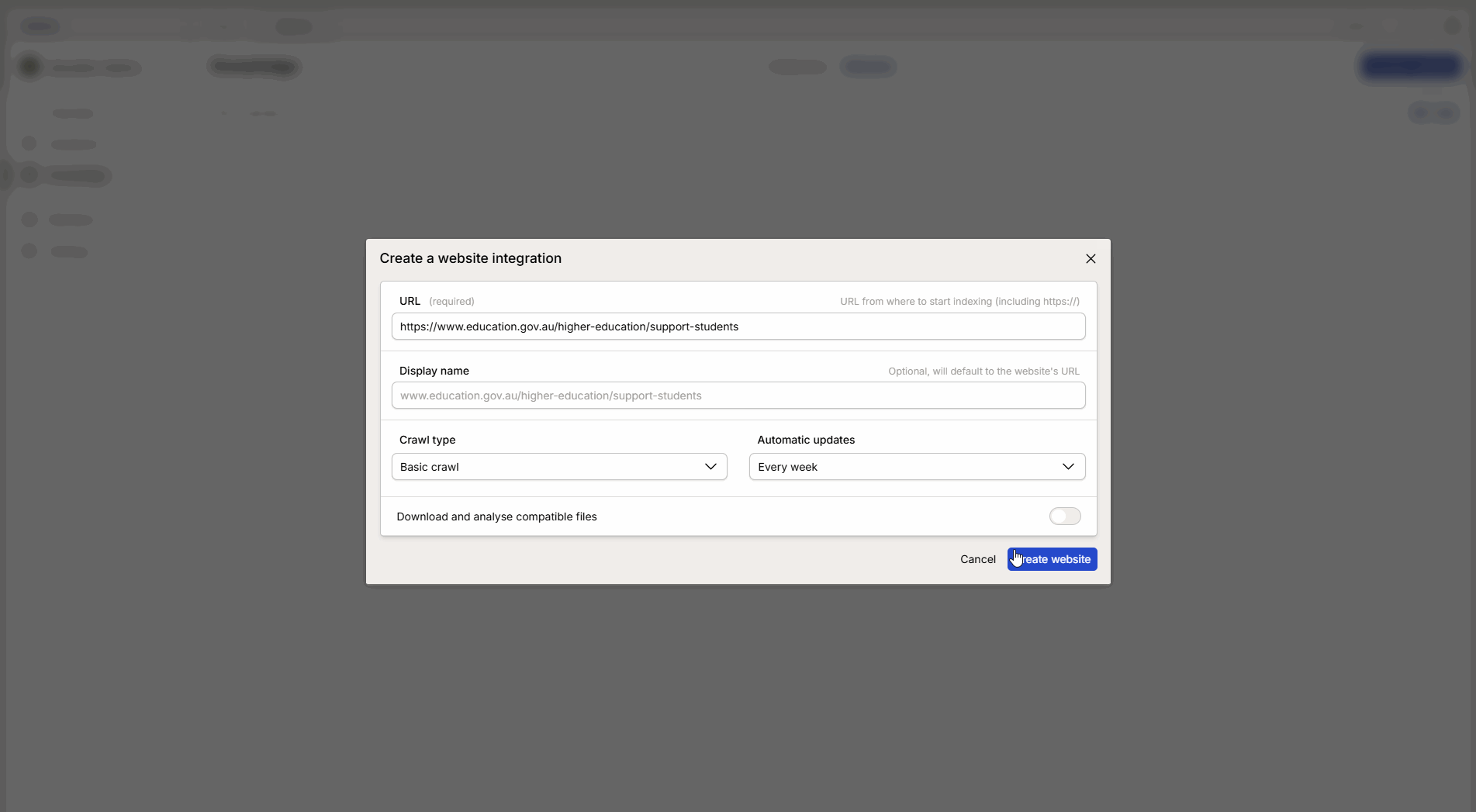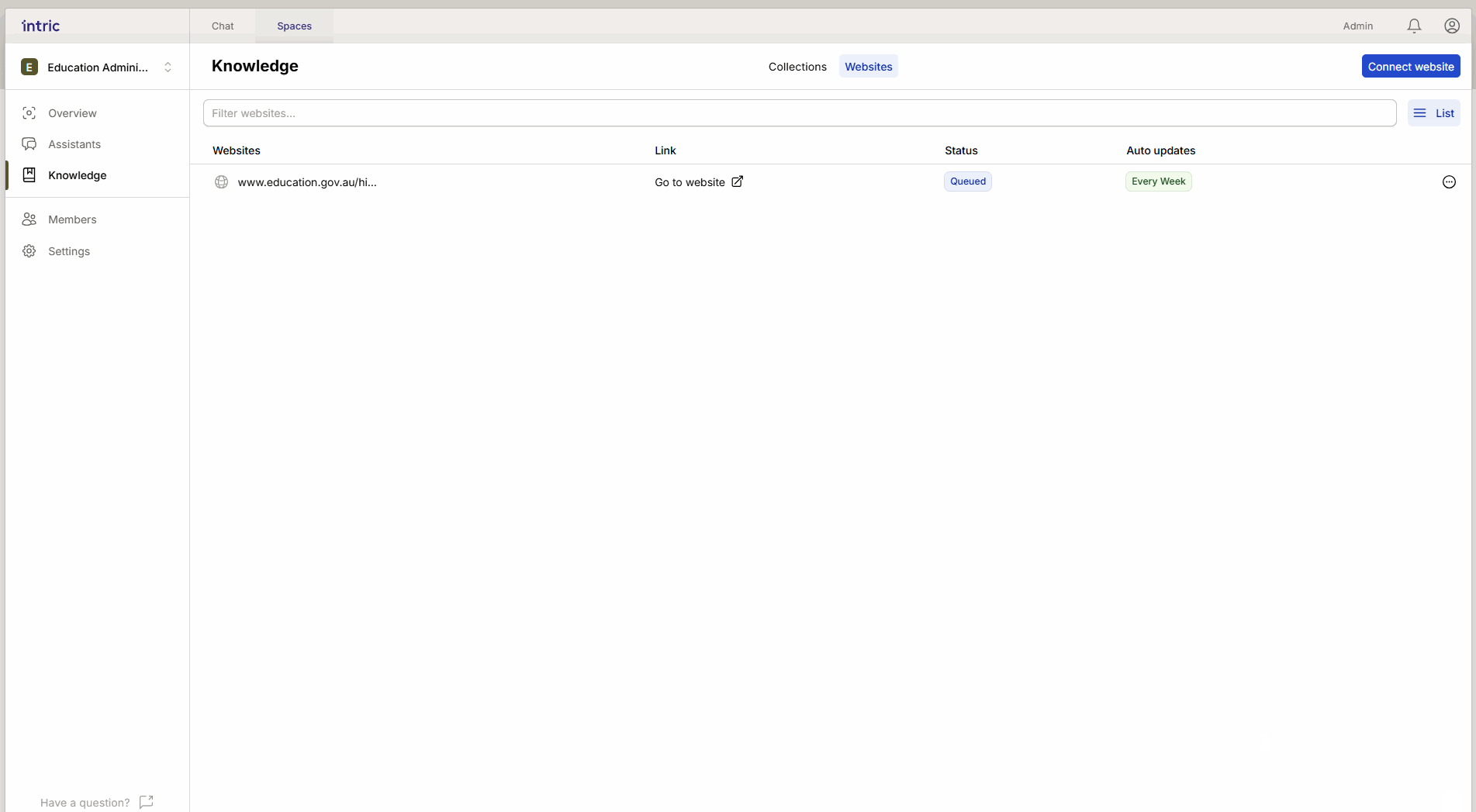
Compila le informazioni nella finestra di configurazione:
URL: Incolla il link al sito web selezionato.
Metodo di crawling: Scegli il metodo che meglio si adatta allo scopo (vedi spiegazione sotto).
Modello di text embedding (Embedding): Seleziona modello.
- Best practice: Attiva solo un modello di embedding per classe di sicurezza per evitare che la conoscenza caricata diventi inaccessibile quando cambi modelli.
Intervallo di aggiornamento: Scegli quanto spesso Intric dovrebbe recuperare nuove informazioni dalla pagina.
Suggerimento: Un URL più specifico spesso dà risultati migliori. È più efficiente scegliere un sottodominio o percorso specifico con informazioni rilevanti (ad esempio,
intric.ai/docs) piuttosto che un intero sito web (intric.ai).
Approfondimento: Metodo – Crawling
Crawling significa che Intric legge sistematicamente le pagine su un sito web. Ci sono due metodi per controllare come Intric trova contenuti:
- Basic Crawl: Intric inizia all’URL specificato e poi segue link interni per scoprire nuovo contenuto. Funziona approssimativamente come un visitatore umano che clicca da pagina a pagina.
- Sitemap: Intric legge la “tabella dei contenuti” del sito web (un file sitemap.xml). Questo è efficiente per siti web molto grandi, ma richiede che il sito web abbia un file sitemap configurato correttamente.
| Metodo | Vantaggi | Svantaggi |
|---|---|---|
| Basic Crawl | Autosufficiente e Completo: Trova automaticamente tutto il contenuto che un utente può vedere. Non richiede configurazione tecnica del sito web. | Intensivo in risorse: Richiede più tempo per indicizzare un’intera pagina e c’è il rischio che pagine irrilevanti siano crawlizzate se non limiti la profondità. |
| Sitemap | Veloce ed Esatto: Hai pieno controllo su esattamente quali pagine sono indicizzate tramite un file xml. Molto efficiente per siti web grandi. | Dipendenza tecnica: Richiede che il sito web abbia un file sitemap aggiornato correttamente. Non trova nulla che manca dall’elenco. |
Raccomandazione: Nella stragrande maggioranza dei casi, usa “basic crawl”. Non richiede preparazione tecnica del sito web e garantisce che l’assistente trovi tutto il contenuto che è visibile a un utente regolare.