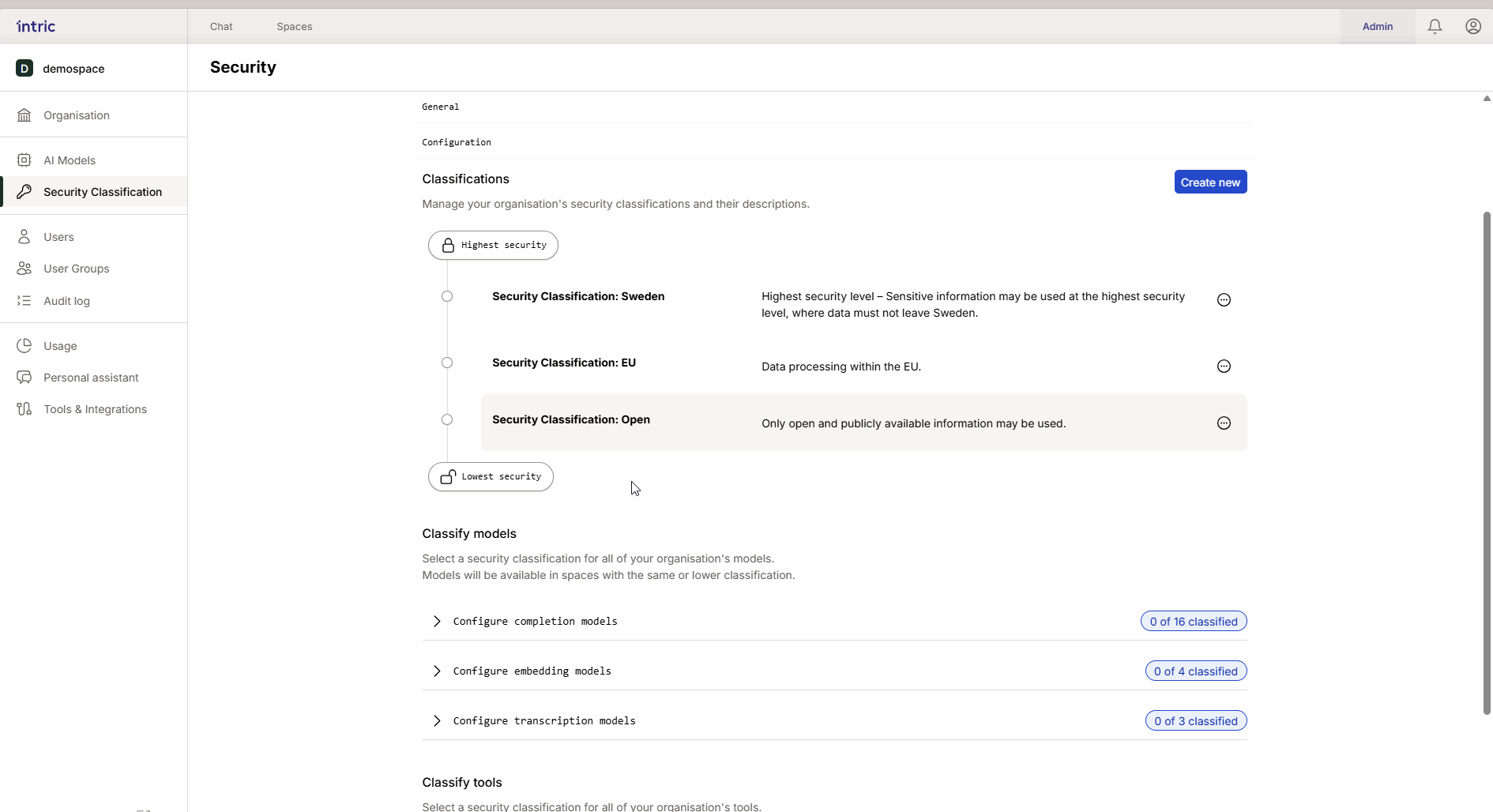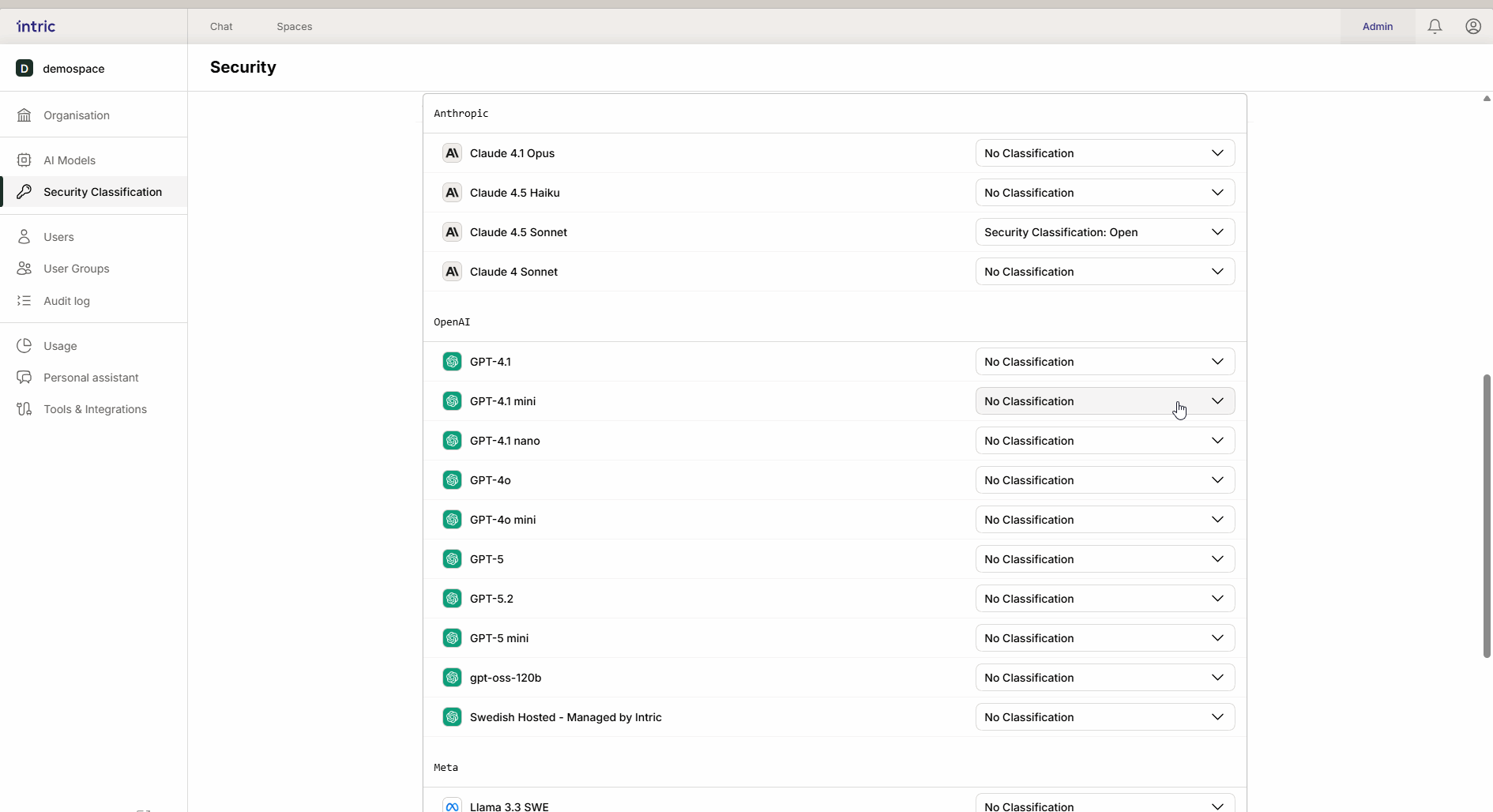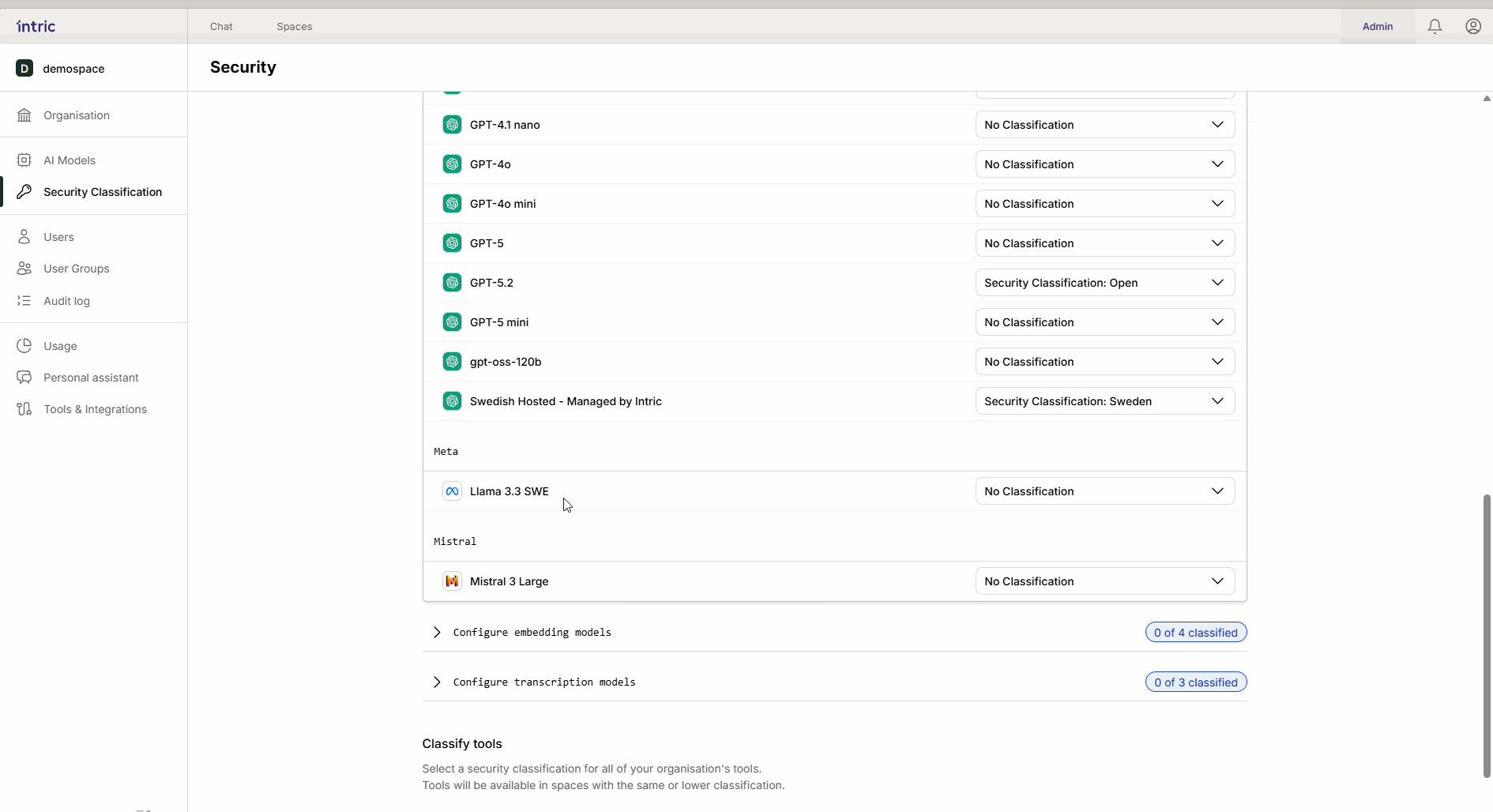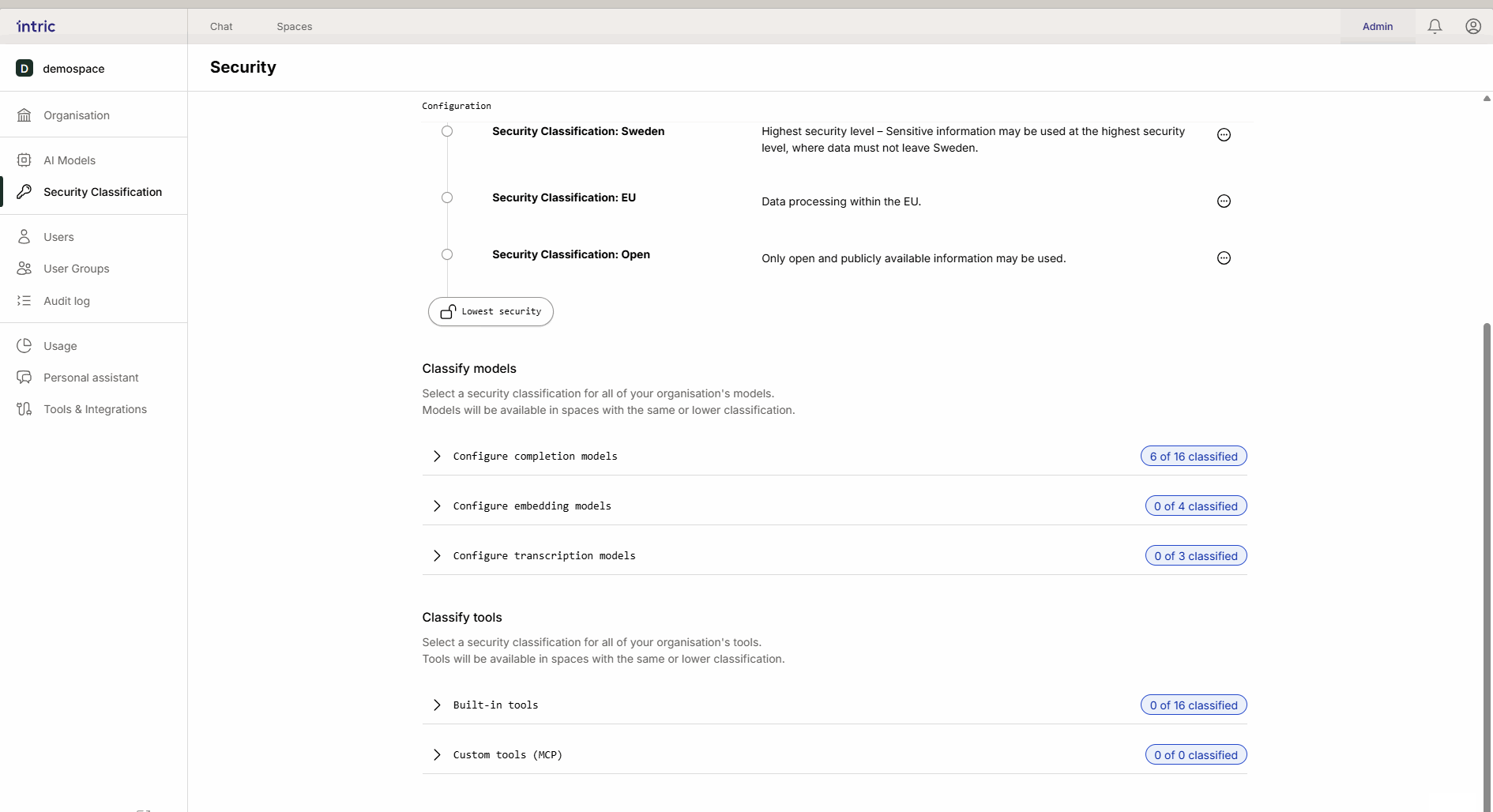
Classificazione del Modello
Diverse attività AI richiedono diversi tipi di modelli. In Intric, classifichi tre tipi principali di modelli per controllare dove i dati possono essere elaborati.
1. Modelli linguistici (LLM)
Questo è il “motore” nell’assistente che crea testo e ragiona. Un modello potente che viene eseguito negli USA (ad esempio, GPT-4o) è spesso classificato più basso (ad esempio, Aperto), mentre un modello che viene eseguito localmente in Svezia o nell’UE può essere classificato più alto (Sensibile/Confidenziale). Grazie all’ereditarietà, il modello locale “sicuro” diventa anche disponibile nello space aperto se desiderato.
2. Modelli di embedding
Questi modelli sono usati per convertire i tuoi documenti (Conoscenza) in dati ricercabili (vettori).
Regola importante: Attiva solo un modello di embedding per classe di sicurezza. Se un utente cambia modelli successivamente, la conoscenza precedentemente caricata può diventare inaccessibile perché i diversi modelli “parlano lingue diverse”.
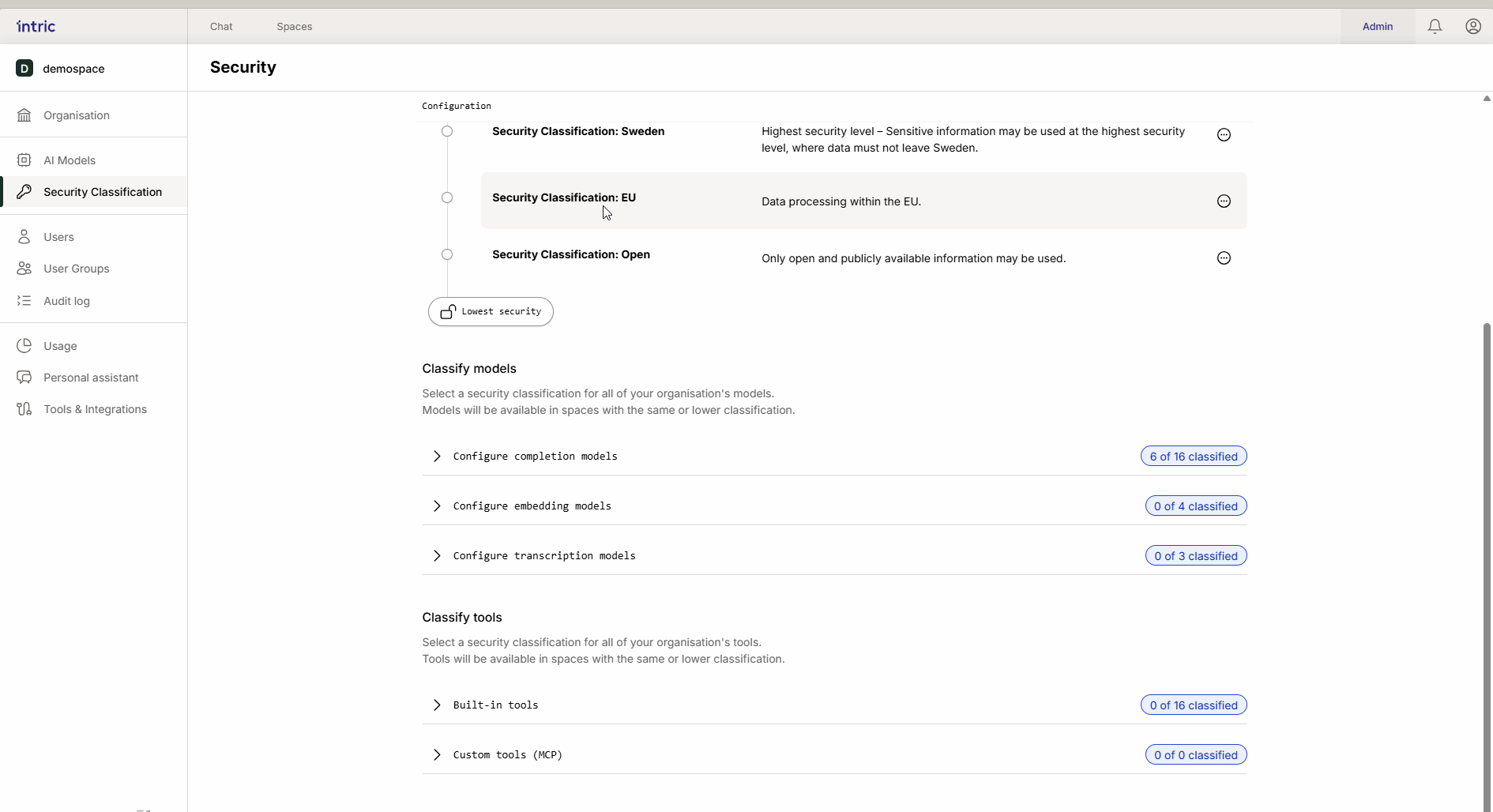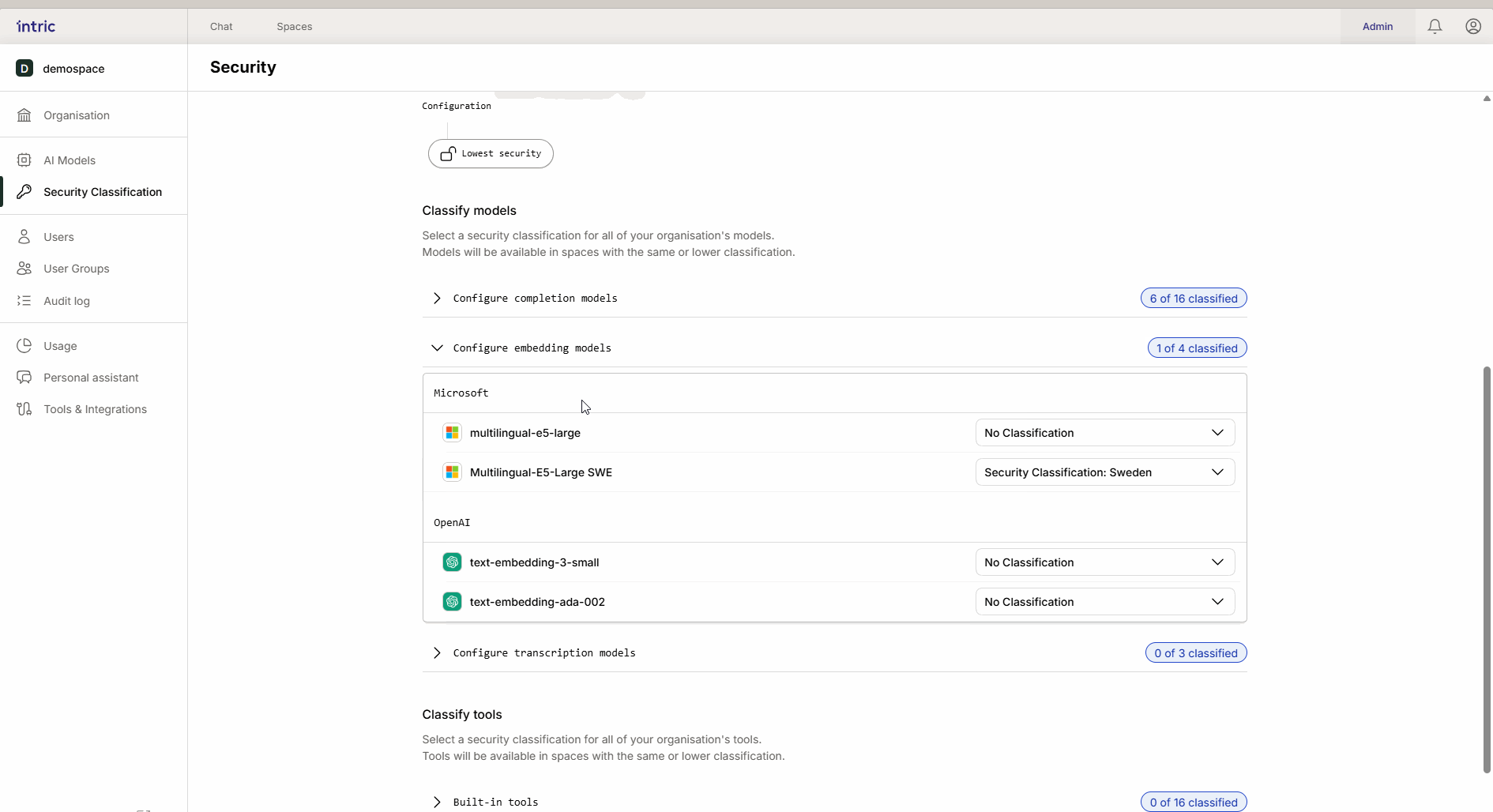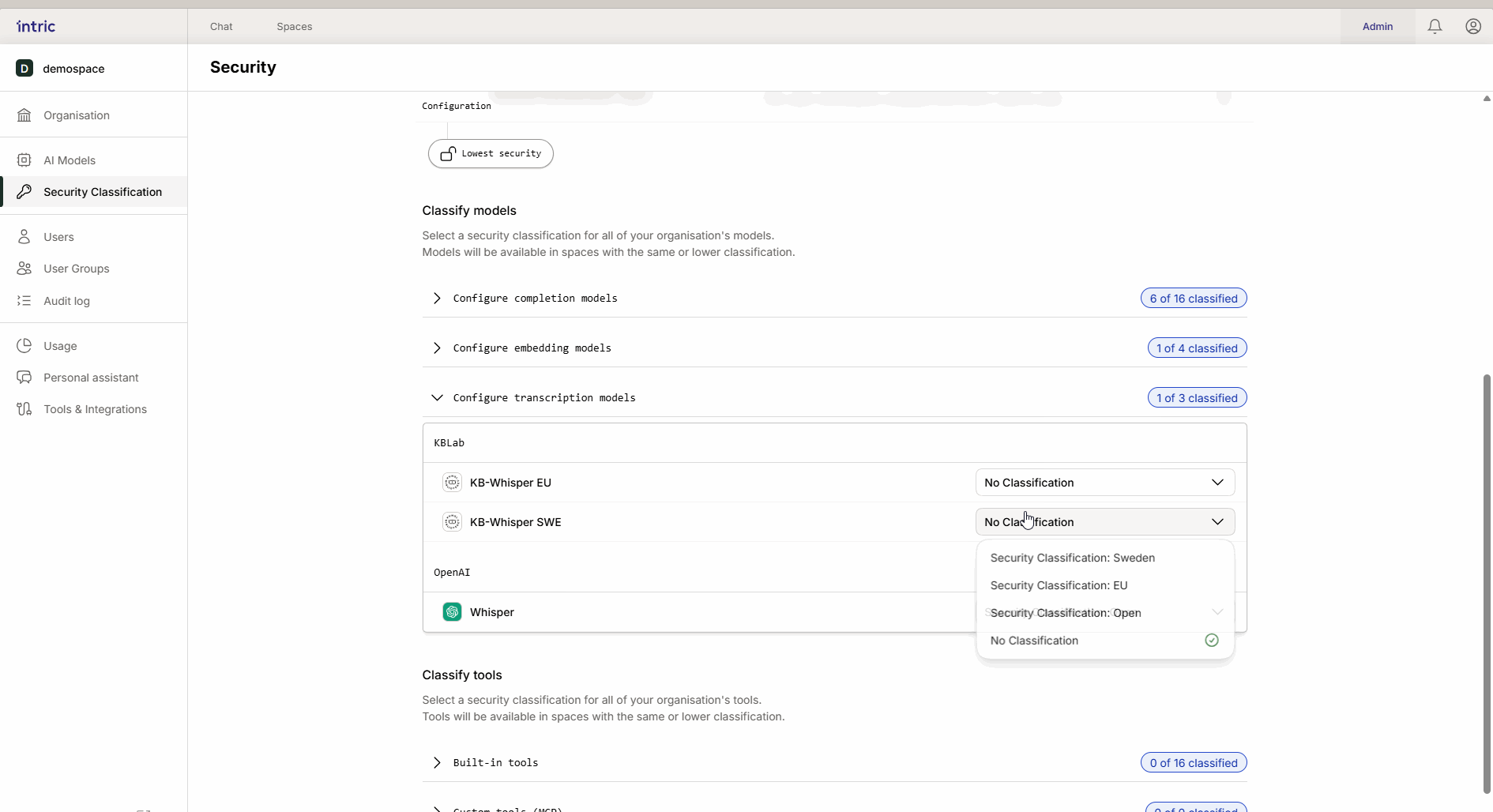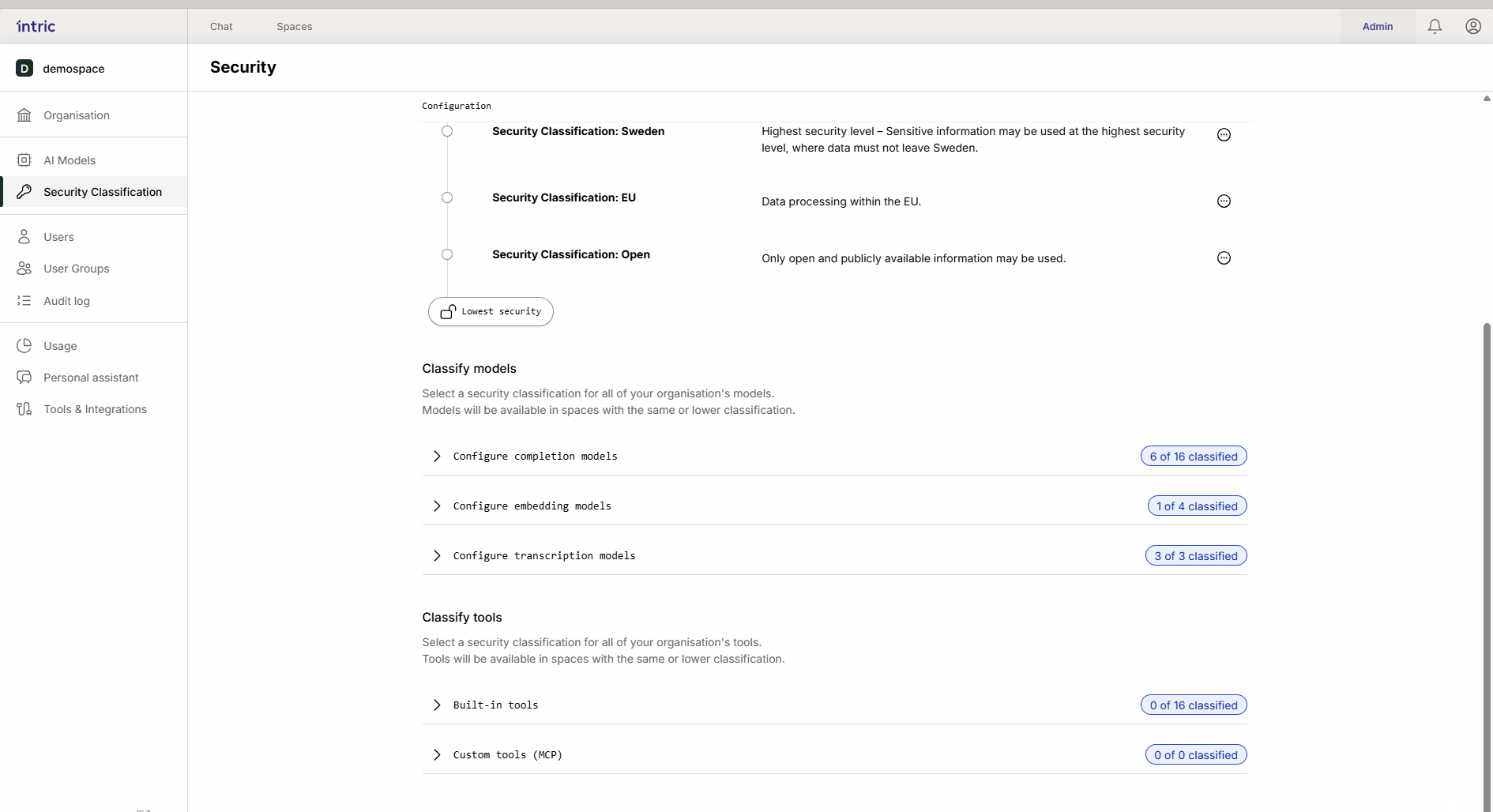
3. Modelli di trascrizione
Usati per convertire il parlato in testo (ad esempio, quando carichi un file audio da un incontro). Mentre il modello linguistico analizza il testo, è il modello di trascrizione che prima “ascolta” il file. Se un incontro contiene informazioni sensibili, il modello di trascrizione deve anche essere classificato di conseguenza.