Model Classification
Different AI tasks require different types of models. In Intric, you classify three main types of models to control where data can be processed.
1. Language models (LLM)
This is the “engine” in the assistant that creates text and reasons. A powerful model that runs in the USA (e.g., GPT-4o) is often classified lower (e.g., Open), while a model that runs locally in Sweden or the EU can be classified higher (Sensitive/Confidential). Thanks to inheritance, the local “secure” model also becomes available in the open space if desired.
2. Embedding models
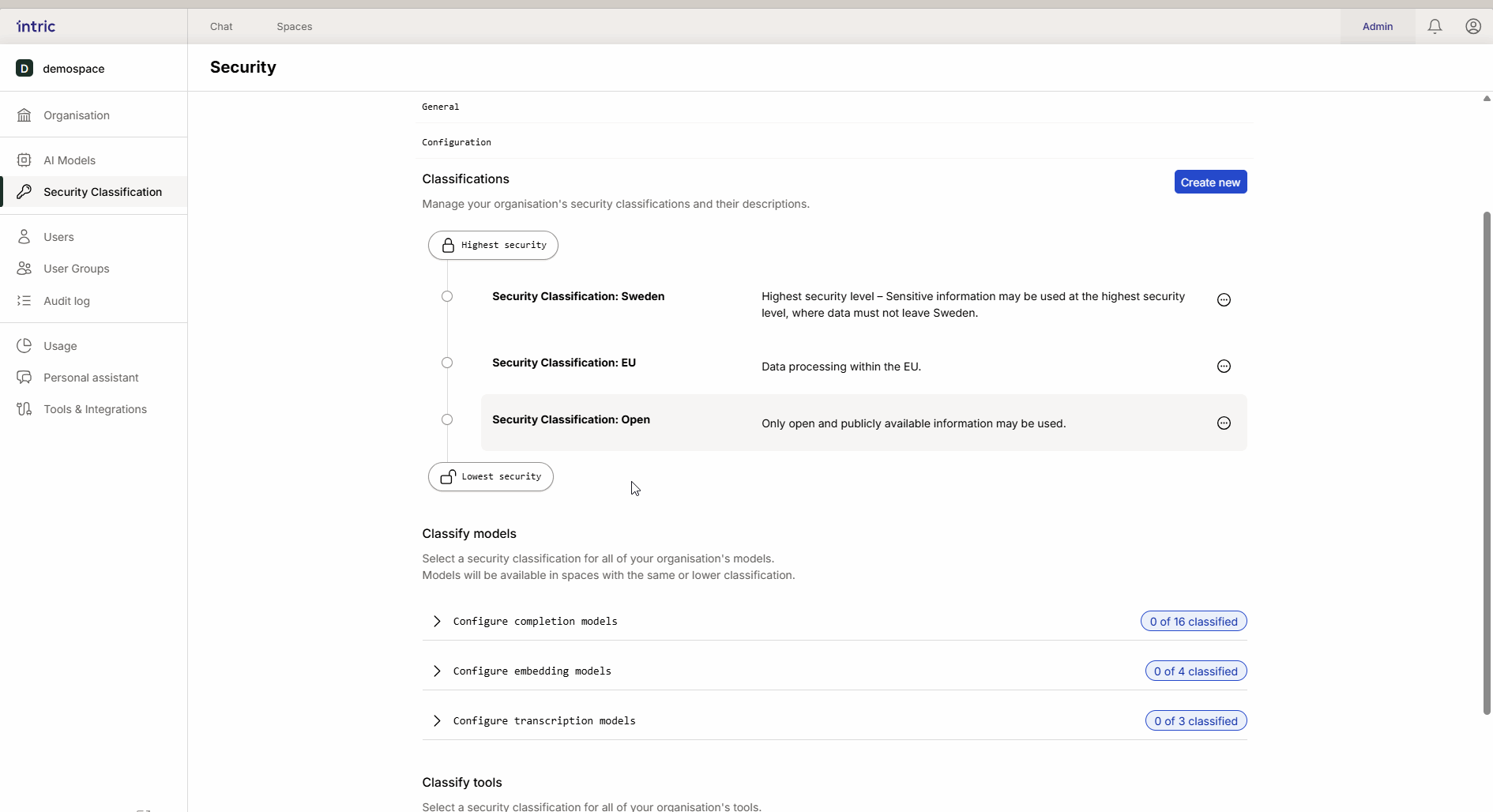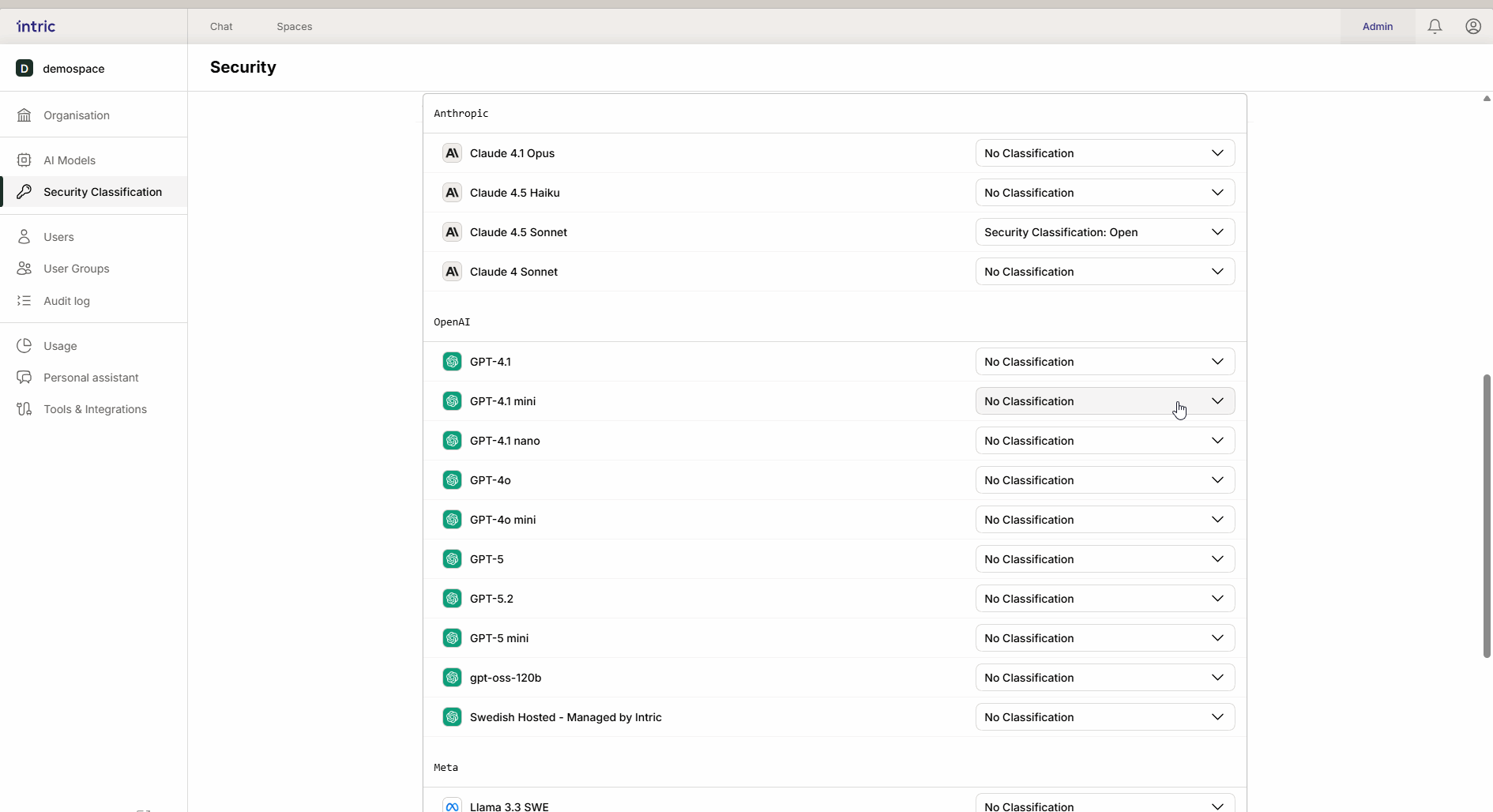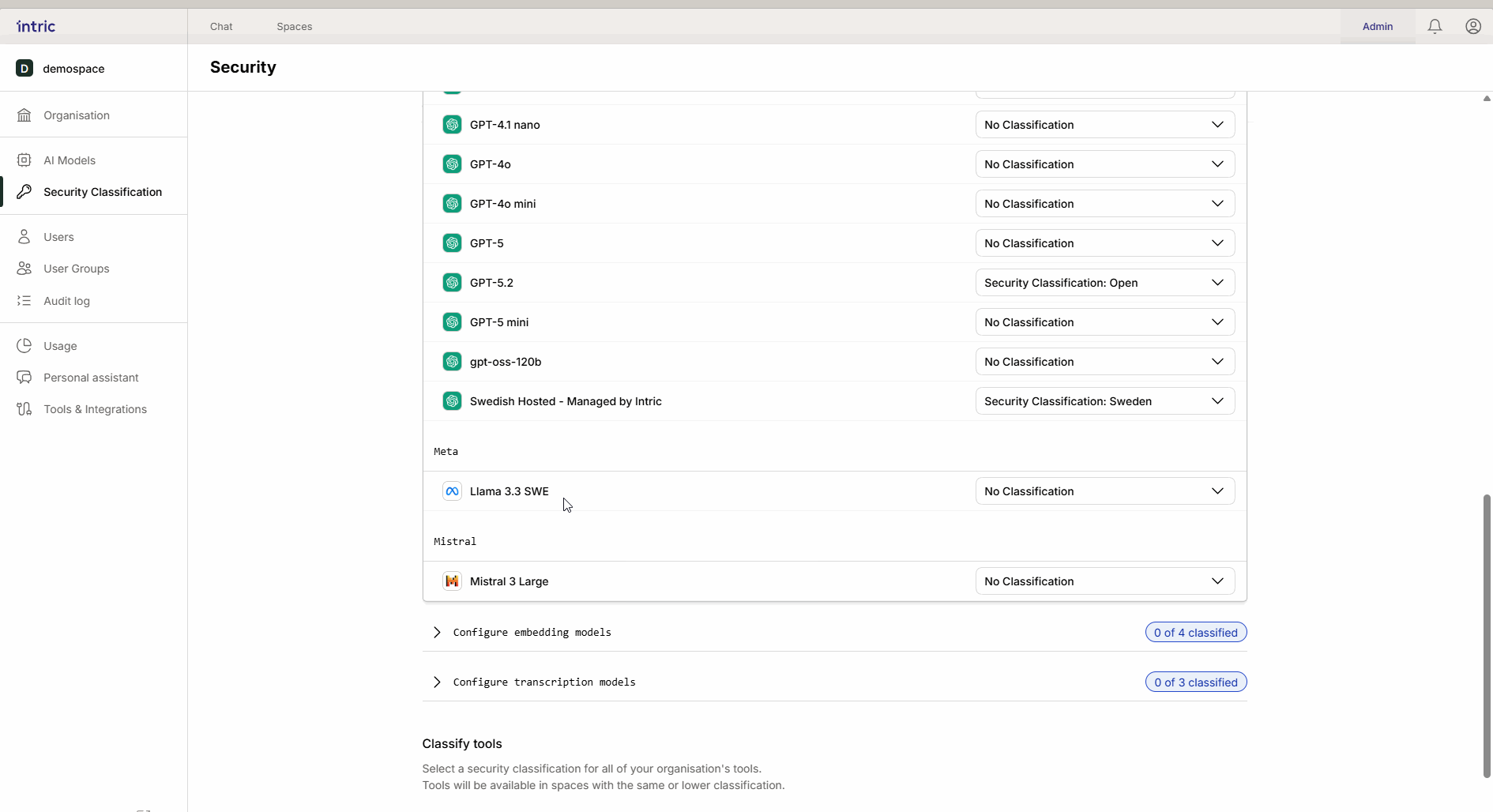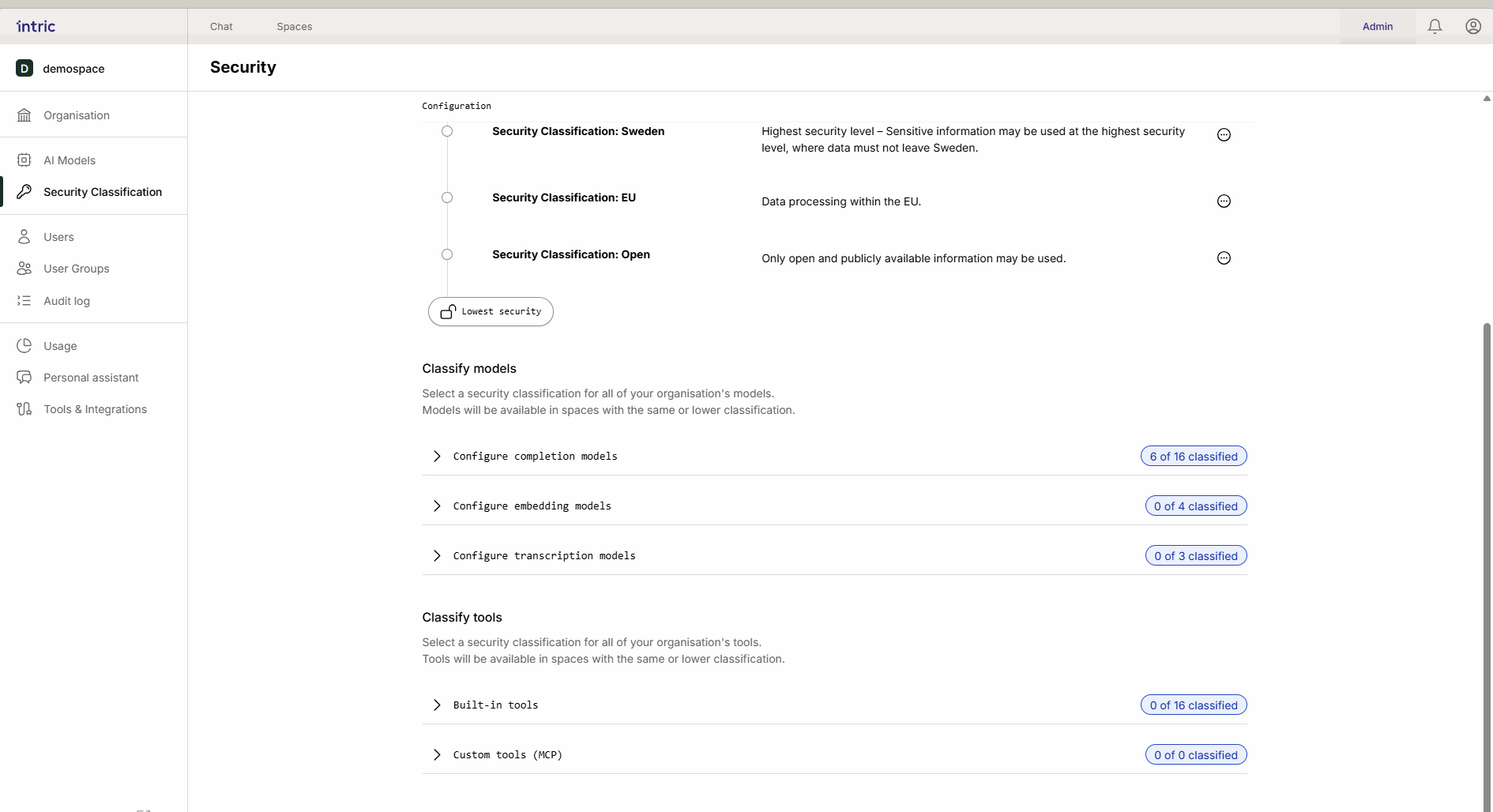
These models are used to convert your documents (Knowledge) into searchable data (vectors).
Important rule: Activate only one embedding model per security class. If a user switches models afterward, previously uploaded knowledge can become inaccessible because the different models “speak different languages.”
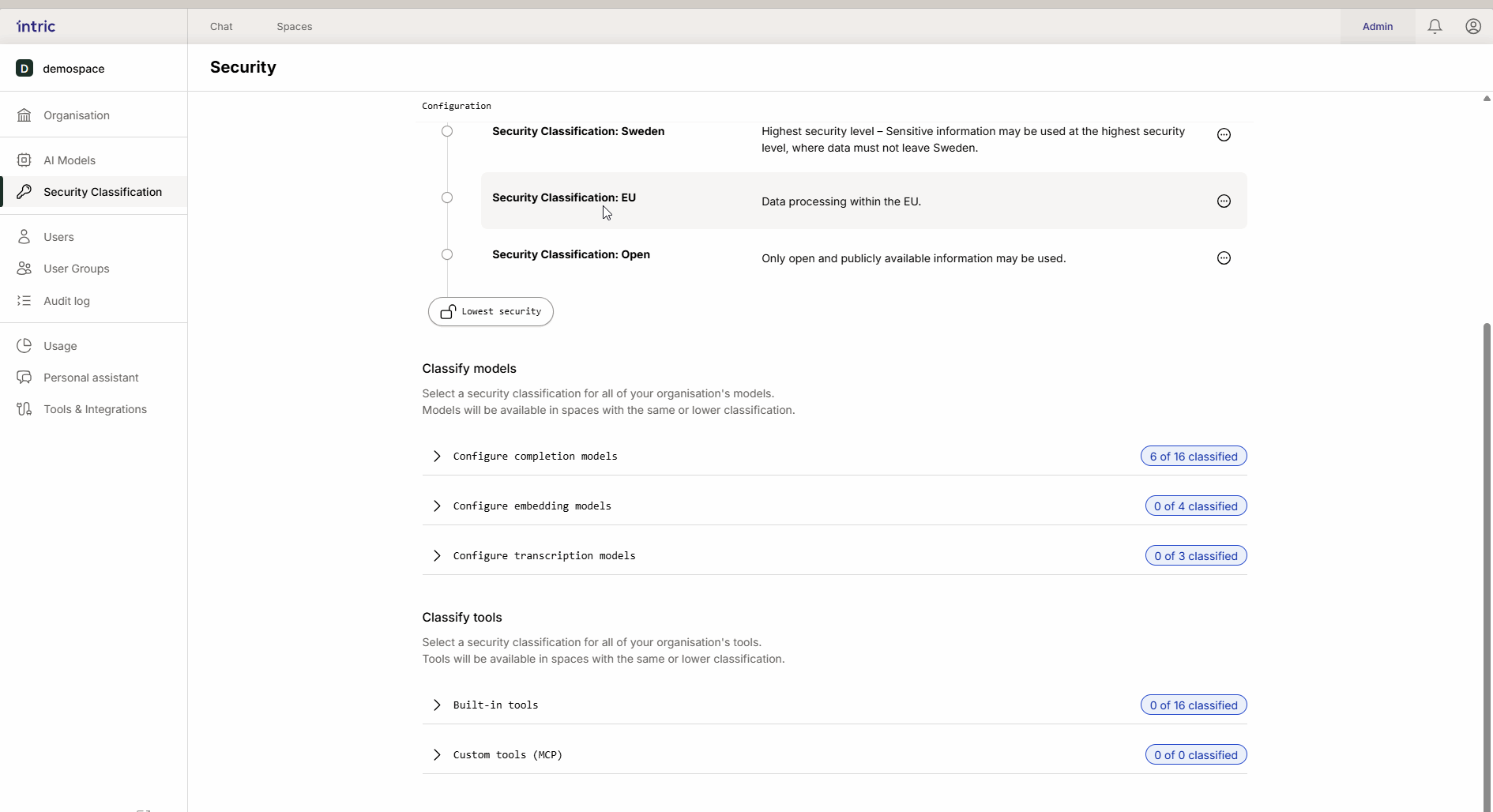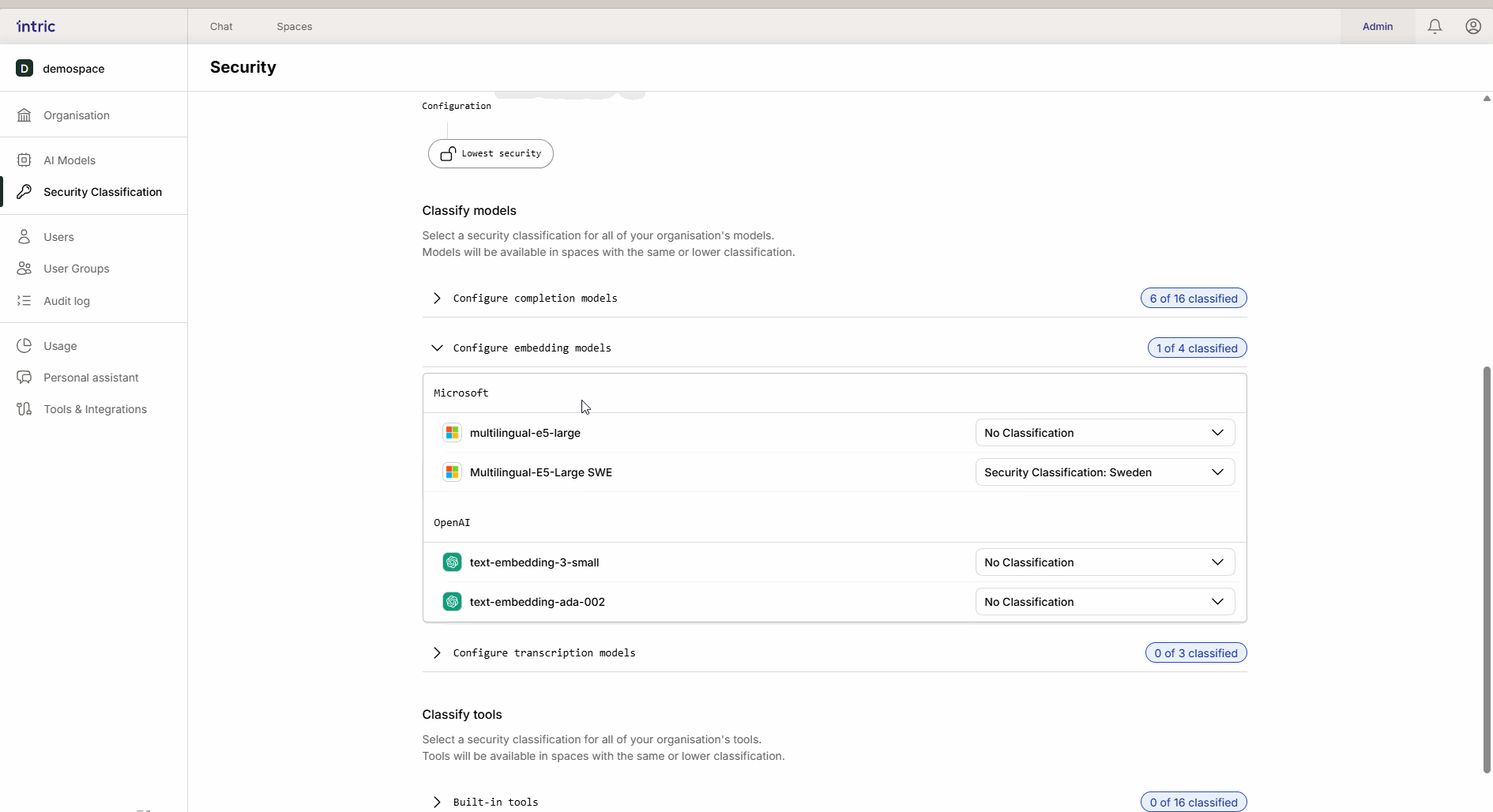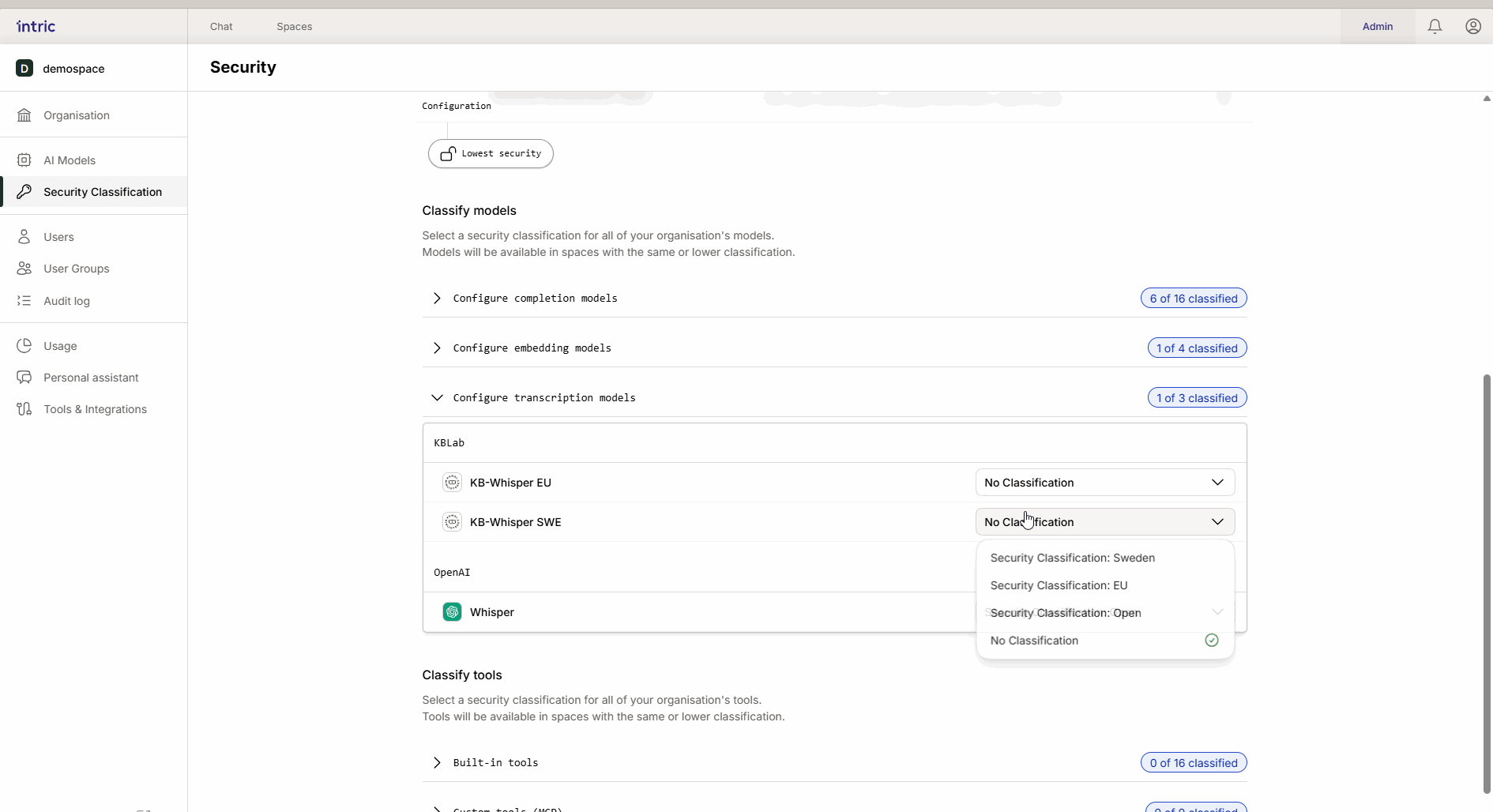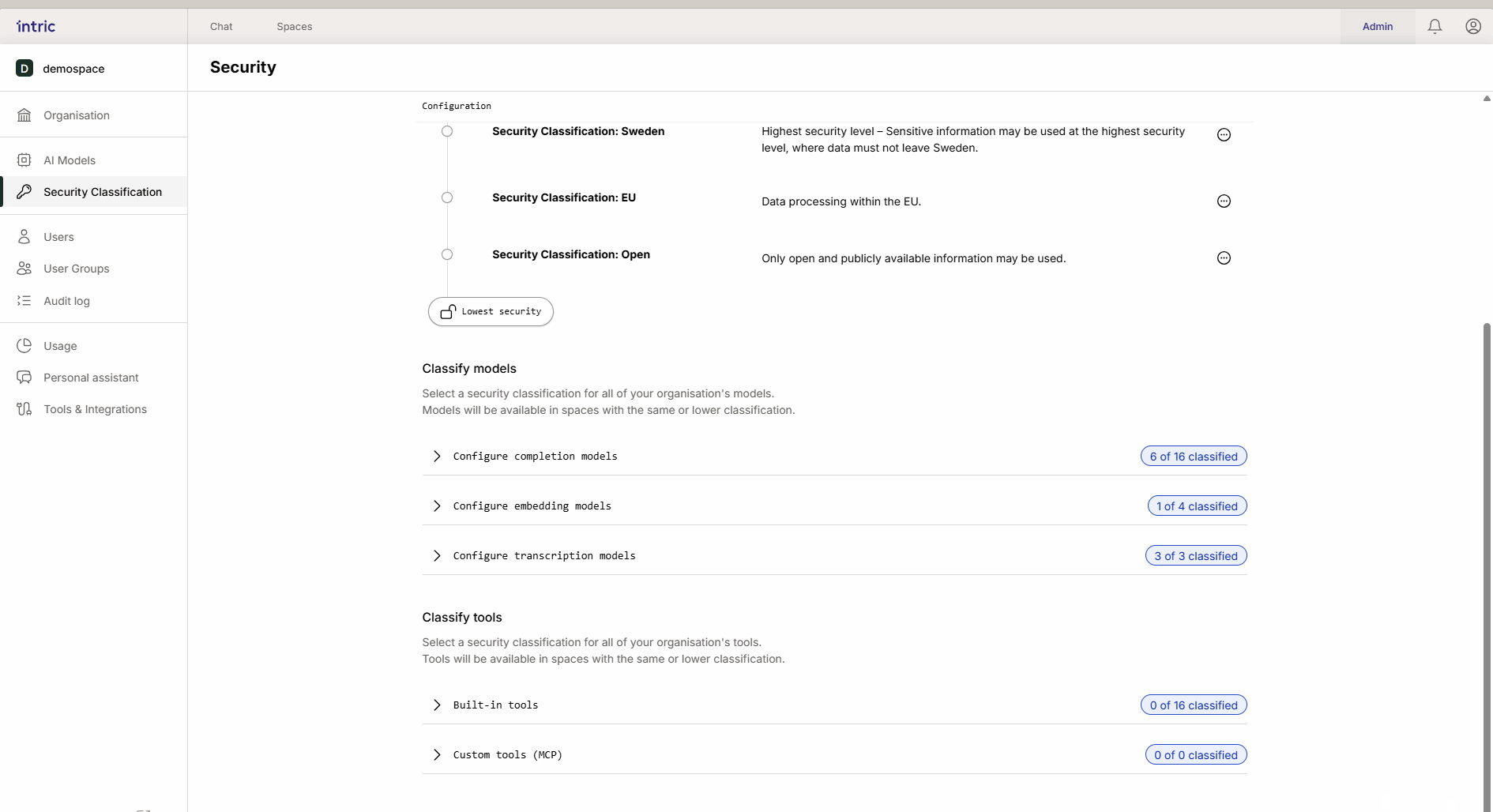
3. Transcription models
Used to convert speech to text (e.g., when you upload an audio file from a meeting). While the language model analyzes the text, it’s the transcription model that first “listens” to the file. If a meeting contains sensitive information, the transcription model must also be classified accordingly.