Websites
Es ist möglich, externe Websites mit Intric zu verbinden, um ihre Informationen als Teil der Wissensbasis der Assistenten zu verwenden. Durch die Indizierung (Crawling) einer Website kann der Assistent Fragen basierend auf spezifischen Inhalten aus deiner Organisation, Dokumentationsseiten oder öffentlichen Ressourcen beantworten.
So geht’s
Melde dich bei Intric an und finde “Websites” im oberen Menü.
Klicke auf den Button “Website verbinden”.
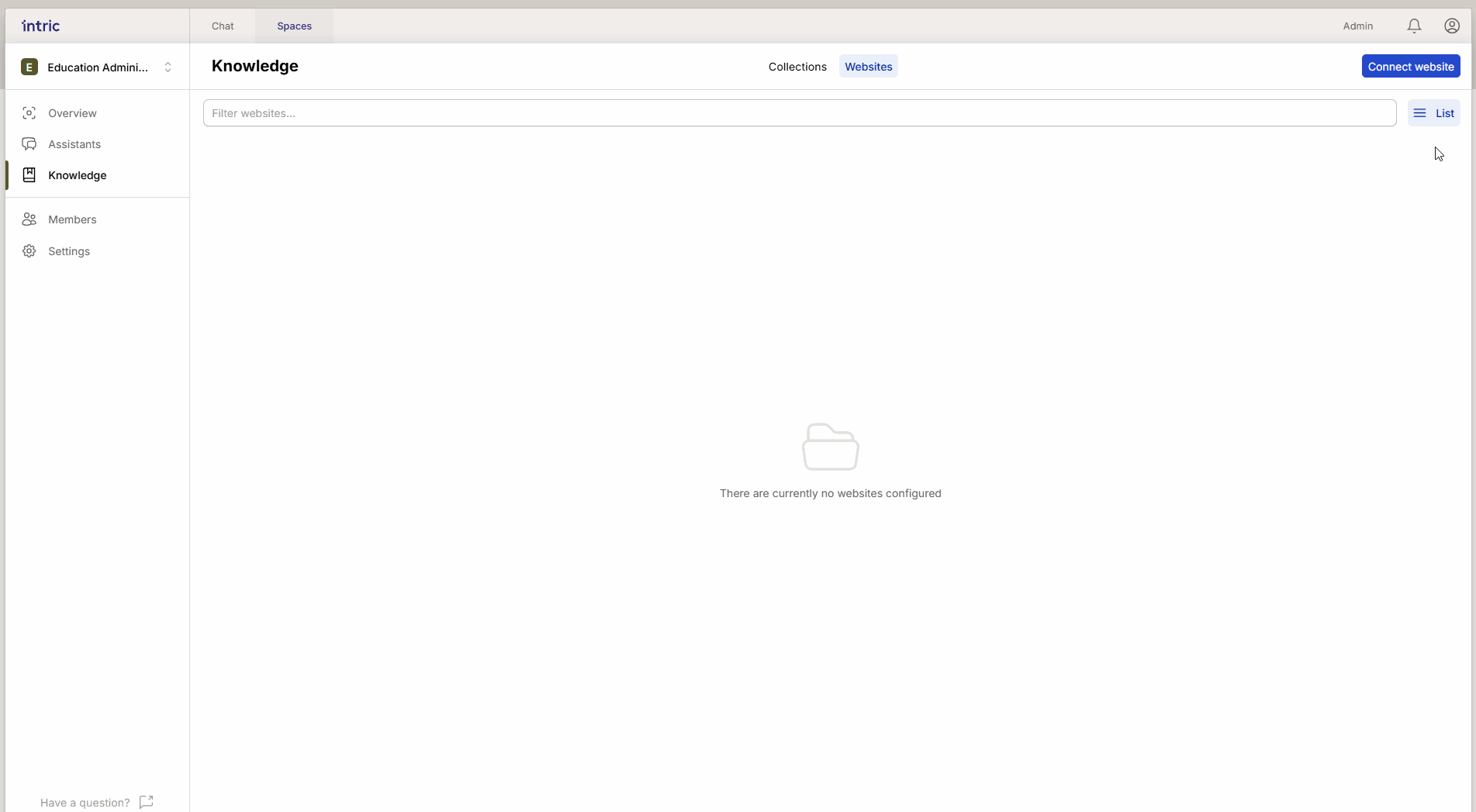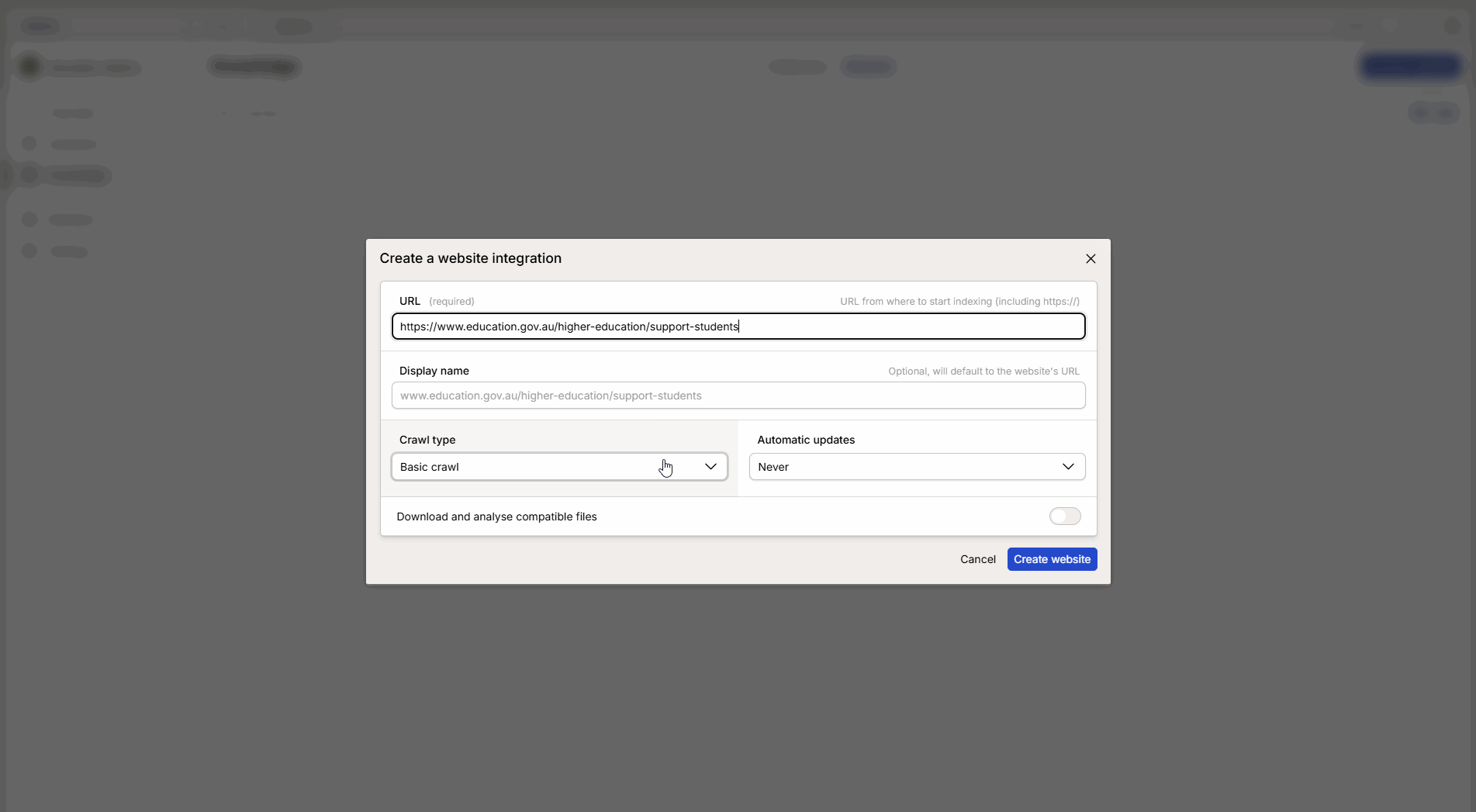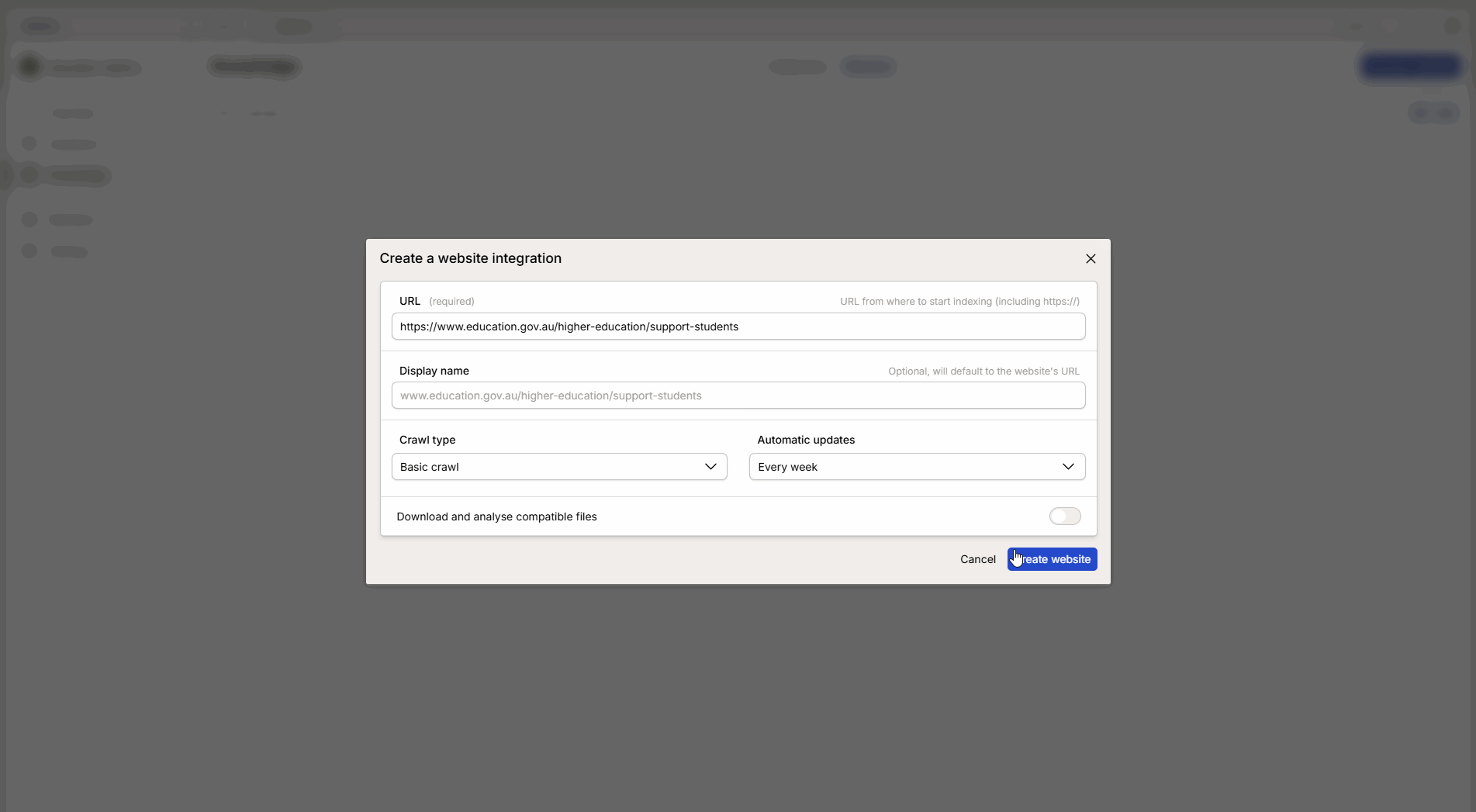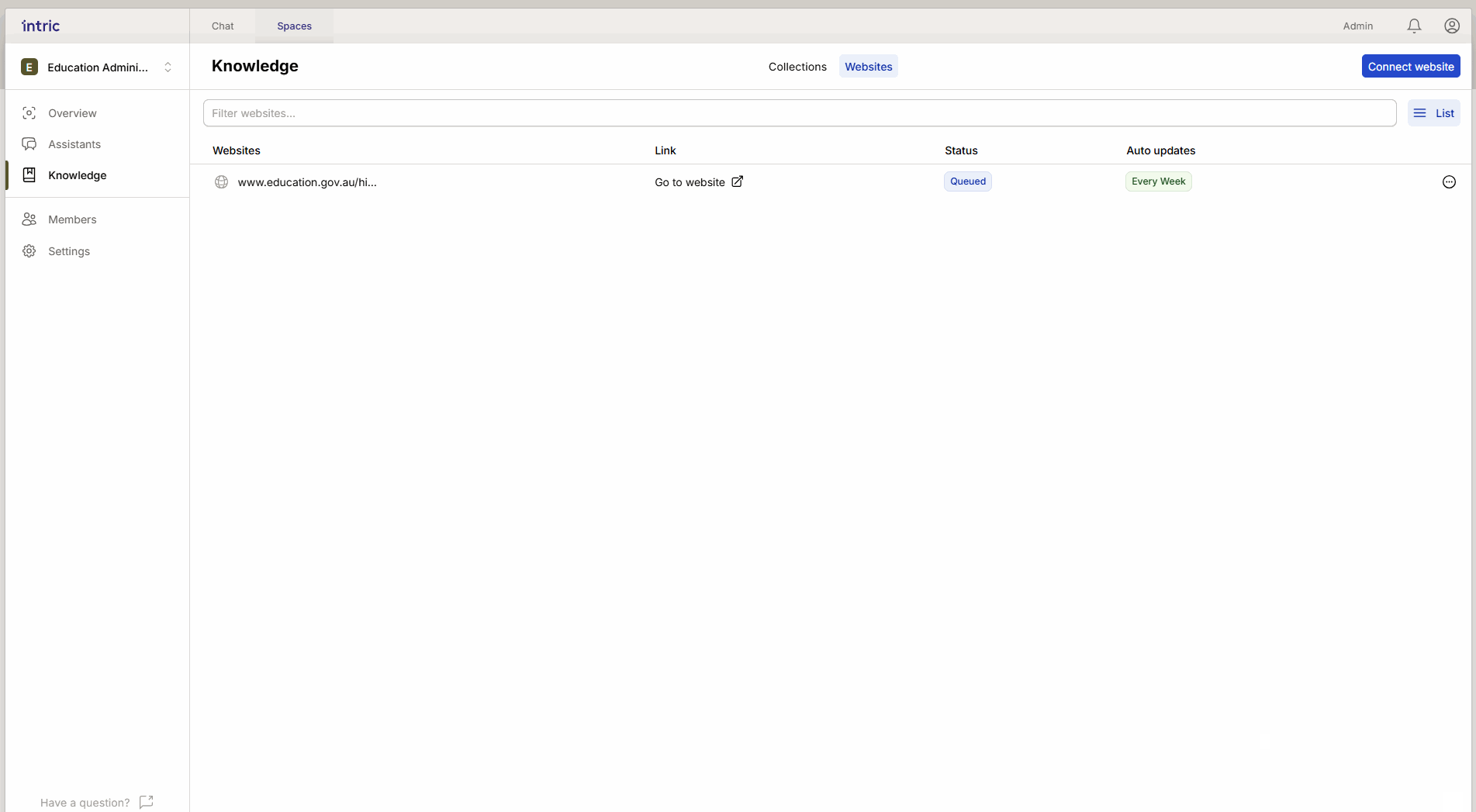
Fülle die Informationen im Konfigurationsfenster aus:
URL: Füge den Link zur ausgewählten Website ein.
Crawl-Methode: Wähle die Methode, die am besten zum Zweck passt (siehe Erklärung unten).
Text-Embedding-Modell (Embedding): Wähle Modell.
- Best Practice: Aktiviere nur ein Embedding-Modell pro Sicherheitsklasse, um zu vermeiden, dass hochgeladenes Wissen unzugänglich wird, wenn Modelle gewechselt werden.
Aktualisierungsintervall: Wähle, wie oft Intric neue Informationen von der Seite abrufen soll.
Tipp: Eine spezifischere URL gibt oft bessere Ergebnisse. Es ist effizienter, eine Subdomain oder einen spezifischen Pfad mit relevanten Informationen zu wählen (z. B.
intric.ai/docs) anstatt eine gesamte Website (intric.ai).
Deep Dive: Methode – Crawling
Crawling bedeutet, dass Intric systematisch die Seiten auf einer Website liest. Es gibt zwei Methoden, um zu steuern, wie Intric Inhalte findet:
- Basic Crawl: Intric startet bei der angegebenen URL und folgt dann internen Links, um neue Inhalte zu entdecken. Es funktioniert ungefähr wie ein menschlicher Besucher, der von Seite zu Seite klickt.
- Sitemap: Intric liest das eigene “Inhaltsverzeichnis” der Website (eine sitemap.xml-Datei). Dies ist effizient für sehr große Websites, erfordert aber, dass die Website eine korrekt konfigurierte Sitemap-Datei hat.
| Methode | Vorteile | Nachteile |
|---|---|---|
| Basic Crawl | Selbstständig & Umfassend: Findet automatisch alle Inhalte, die ein Benutzer sehen kann. Erfordert keine technische Konfiguration der Website. | Ressourcenintensiv: Dauert länger, eine gesamte Seite zu indizieren, und es besteht das Risiko, dass irrelevante Seiten gecrawlt werden, wenn du die Tiefe nicht begrenzt. |
| Sitemap | Schnell & Exakt: Du hast vollständige Kontrolle darüber, welche Seiten genau über eine XML-Datei indiziert werden. Sehr effizient für große Websites. | Technische Abhängigkeit: Erfordert, dass die Website eine korrekt aktualisierte Sitemap-Datei hat. Findet nichts, was in der Liste fehlt. |
Empfehlung: In der überwiegenden Mehrheit der Fälle verwende “Basic Crawl”. Es erfordert keine technische Vorbereitung der Website und stellt sicher, dass der Assistent alle Inhalte findet, die für einen normalen Benutzer sichtbar sind.