Modellklassifizierung
Verschiedene KI-Aufgaben erfordern verschiedene Arten von Modellen. In Intric klassifizierst du drei Haupttypen von Modellen, um zu steuern, wo Daten verarbeitet werden können.
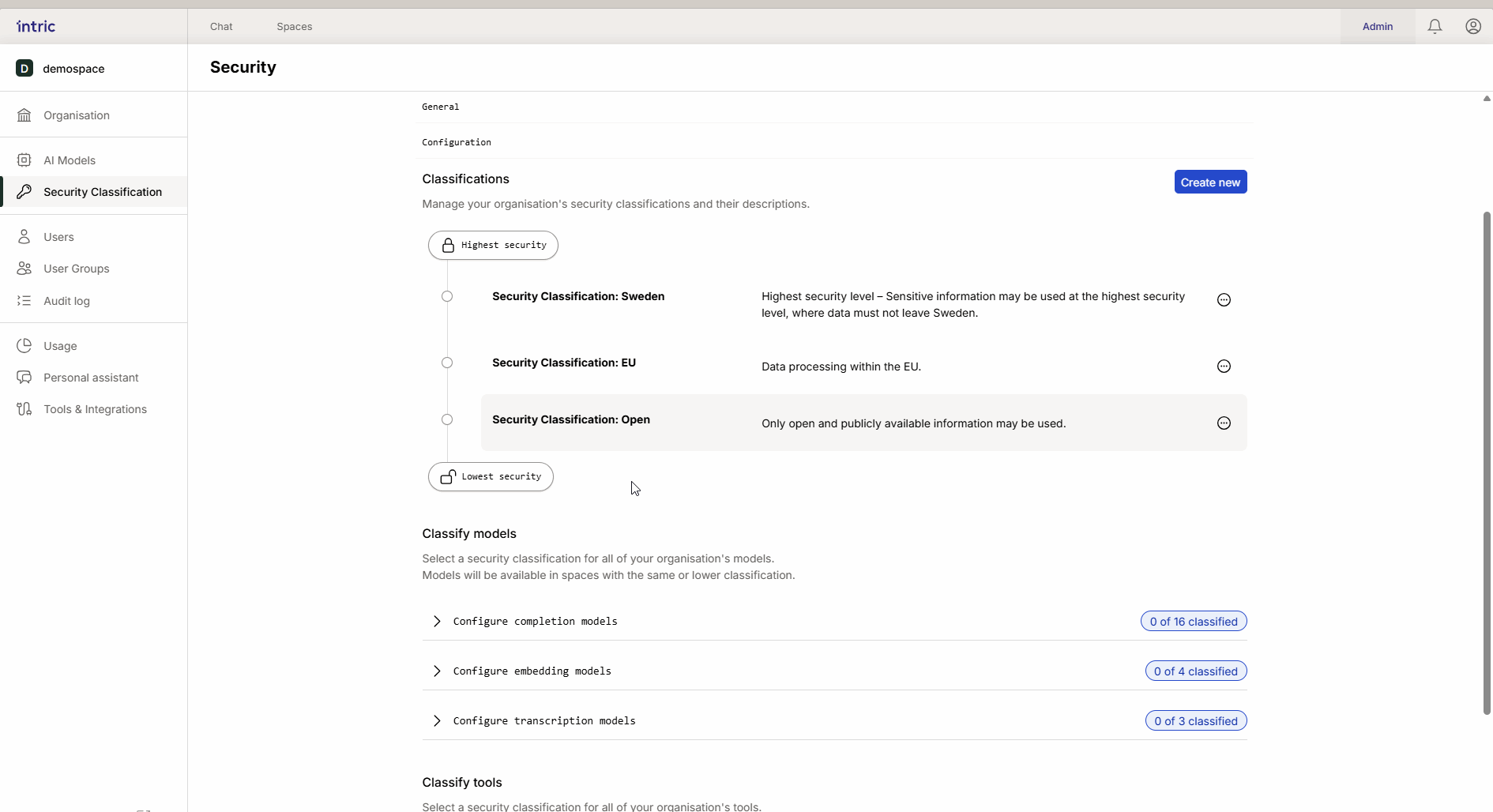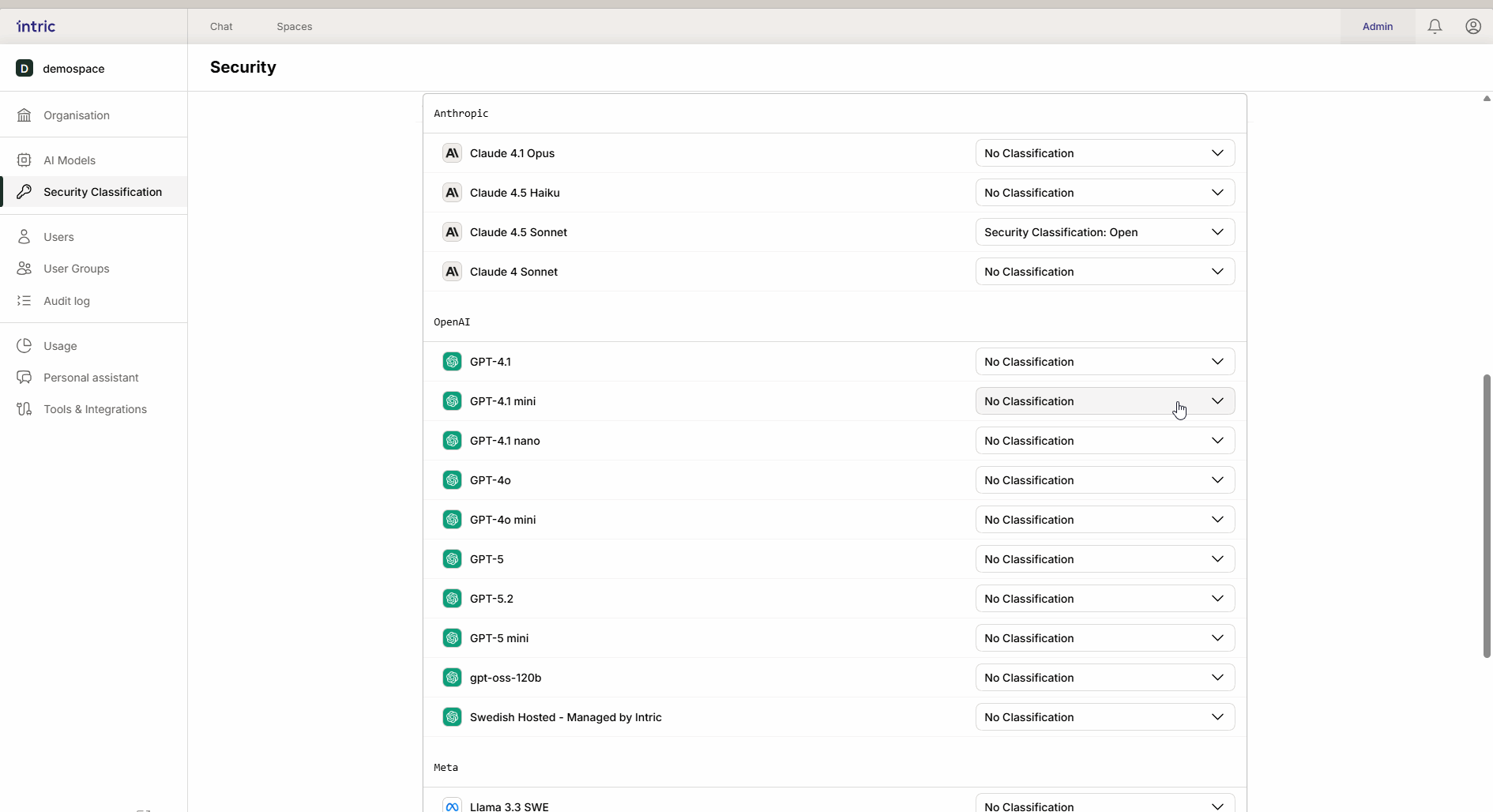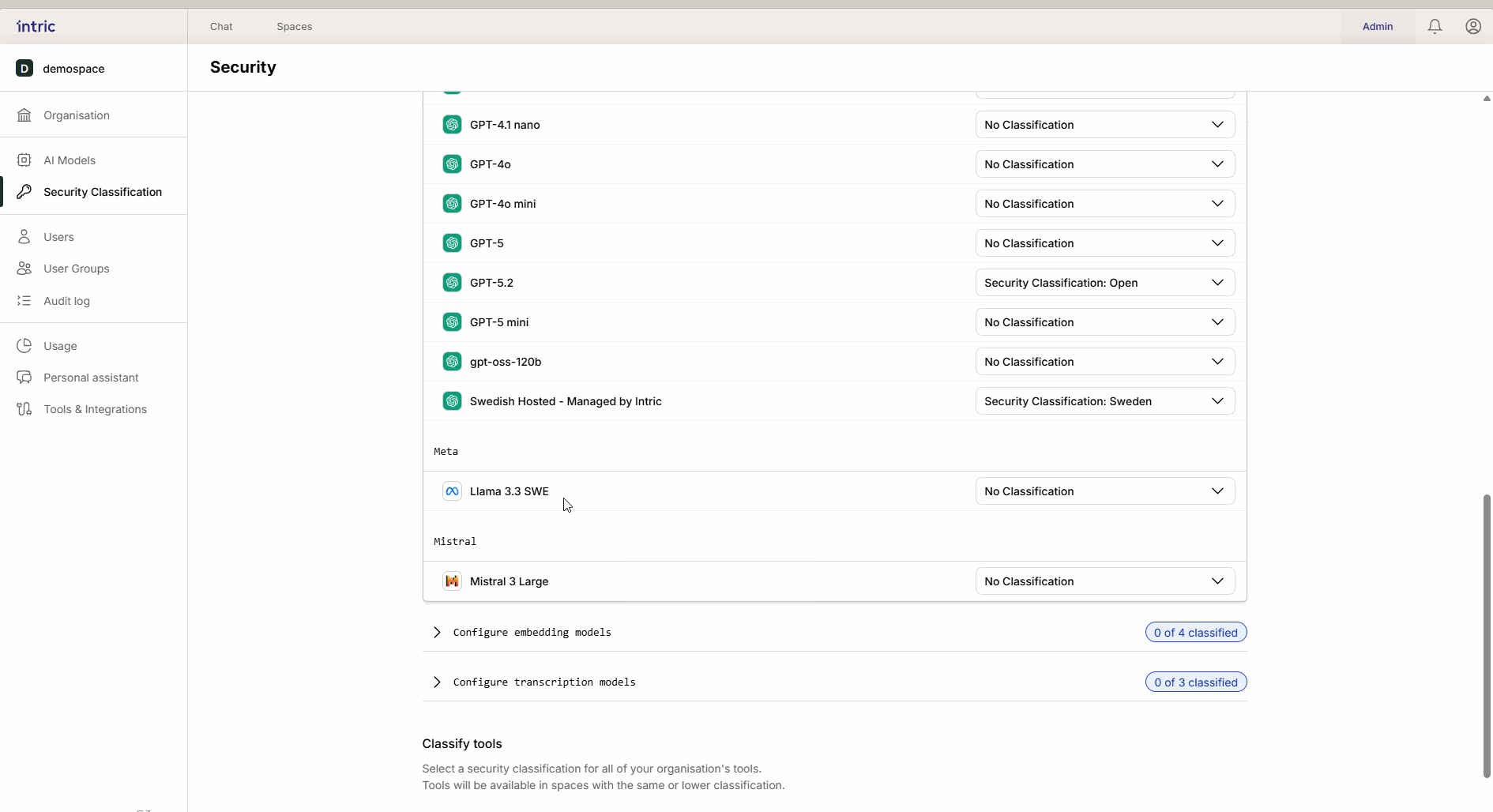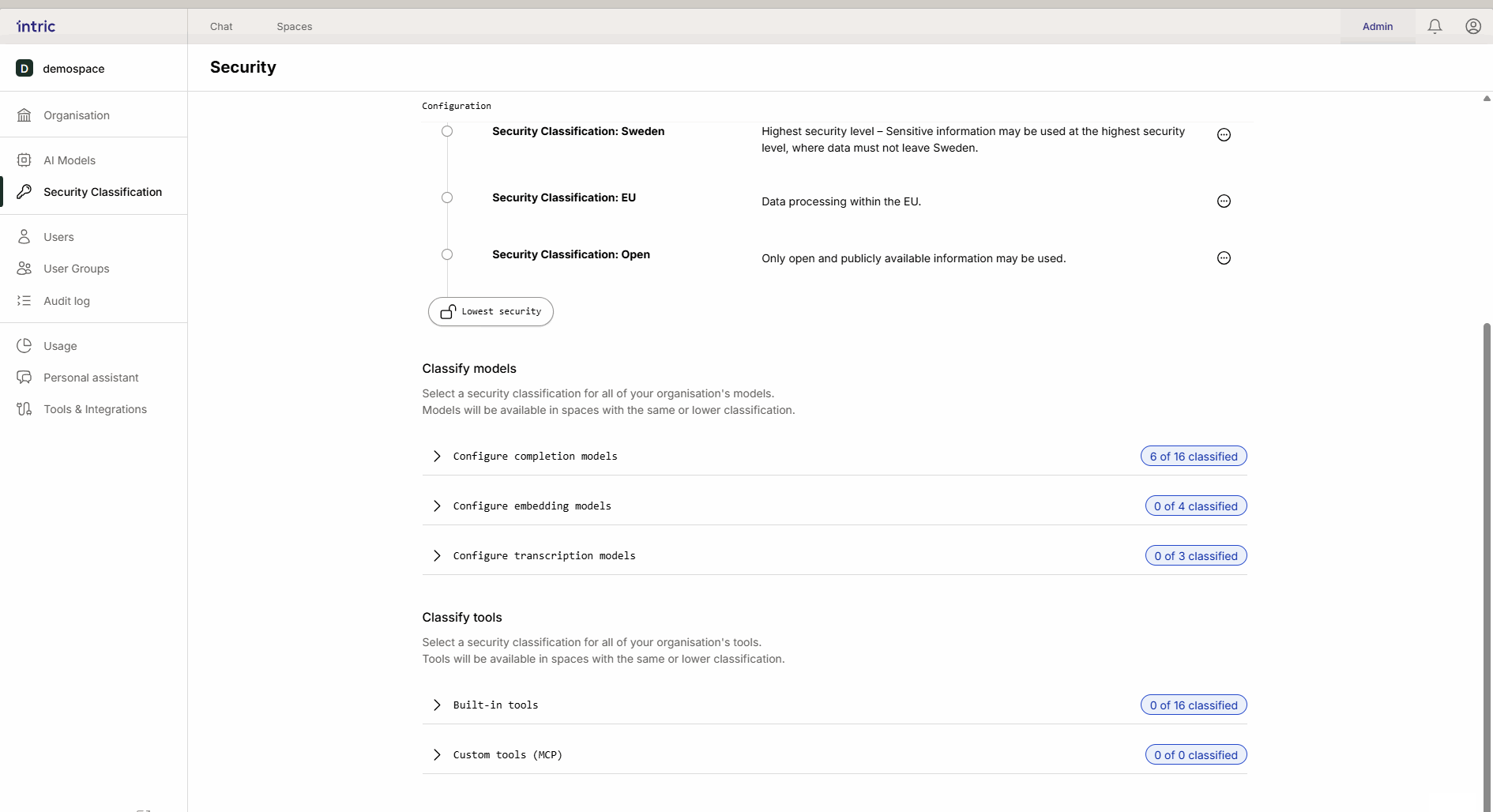
1. Sprachmodelle (LLM)
Dies ist die “Engine” im Assistenten, die Text erstellt und schlussfolgert. Ein leistungsstarkes Modell, das in den USA läuft (z. B. GPT-4o), wird oft niedriger klassifiziert (z. B. Offen), während ein Modell, das lokal in Schweden oder der EU läuft, höher klassifiziert werden kann (Sensibel/Vertraulich). Dank der Vererbung wird das lokale “sichere” Modell auch im offenen Space verfügbar, wenn gewünscht.
2. Embedding-Modelle
Diese Modelle werden verwendet, um deine Dokumente (Wissen) in durchsuchbare Daten (Vektoren) zu konvertieren.
Wichtige Regel: Aktiviere nur ein Embedding-Modell pro Sicherheitsklasse. Wenn ein Benutzer danach Modelle wechselt, kann zuvor hochgeladenes Wissen unzugänglich werden, da die verschiedenen Modelle “verschiedene Sprachen sprechen”.
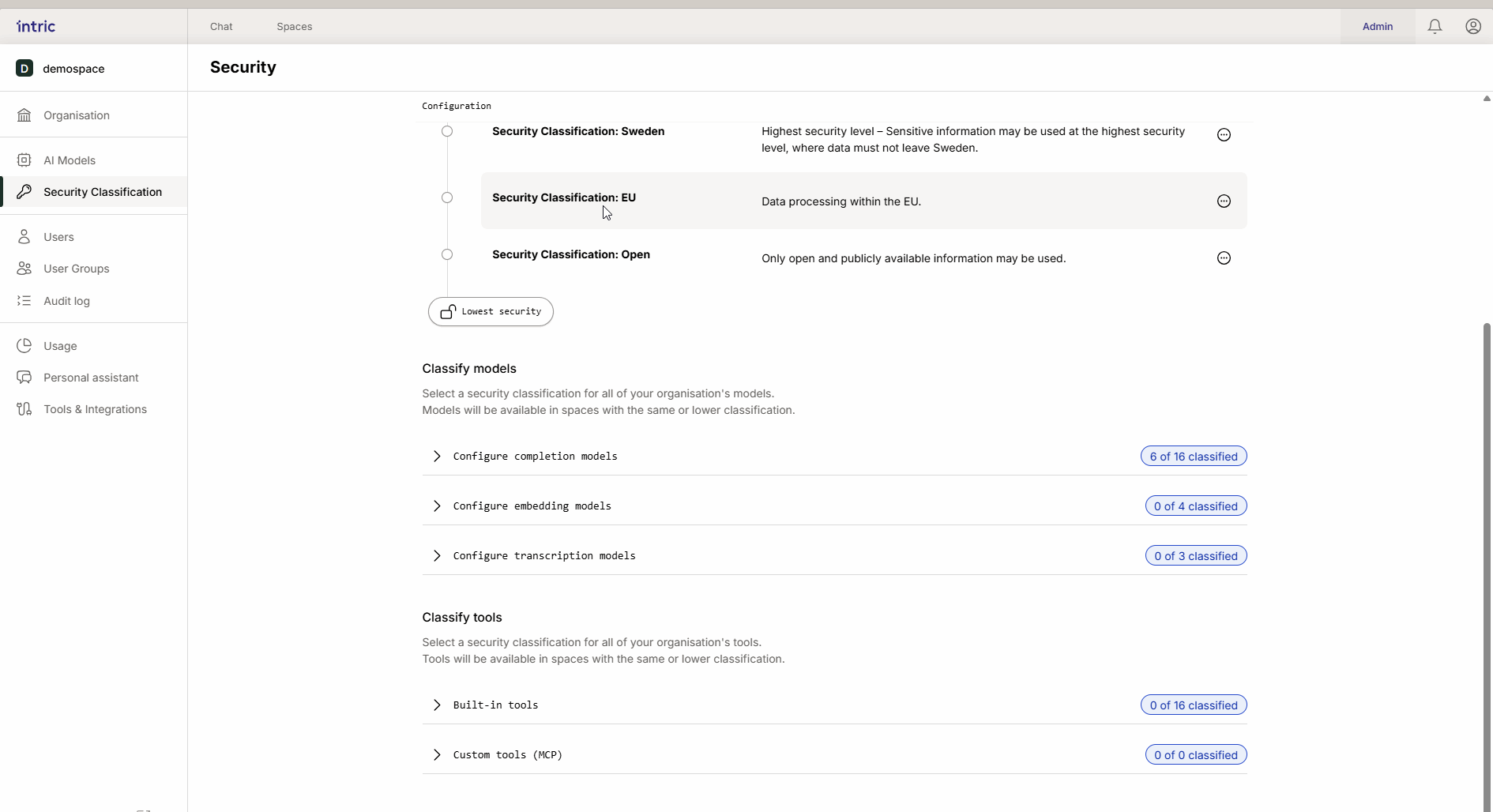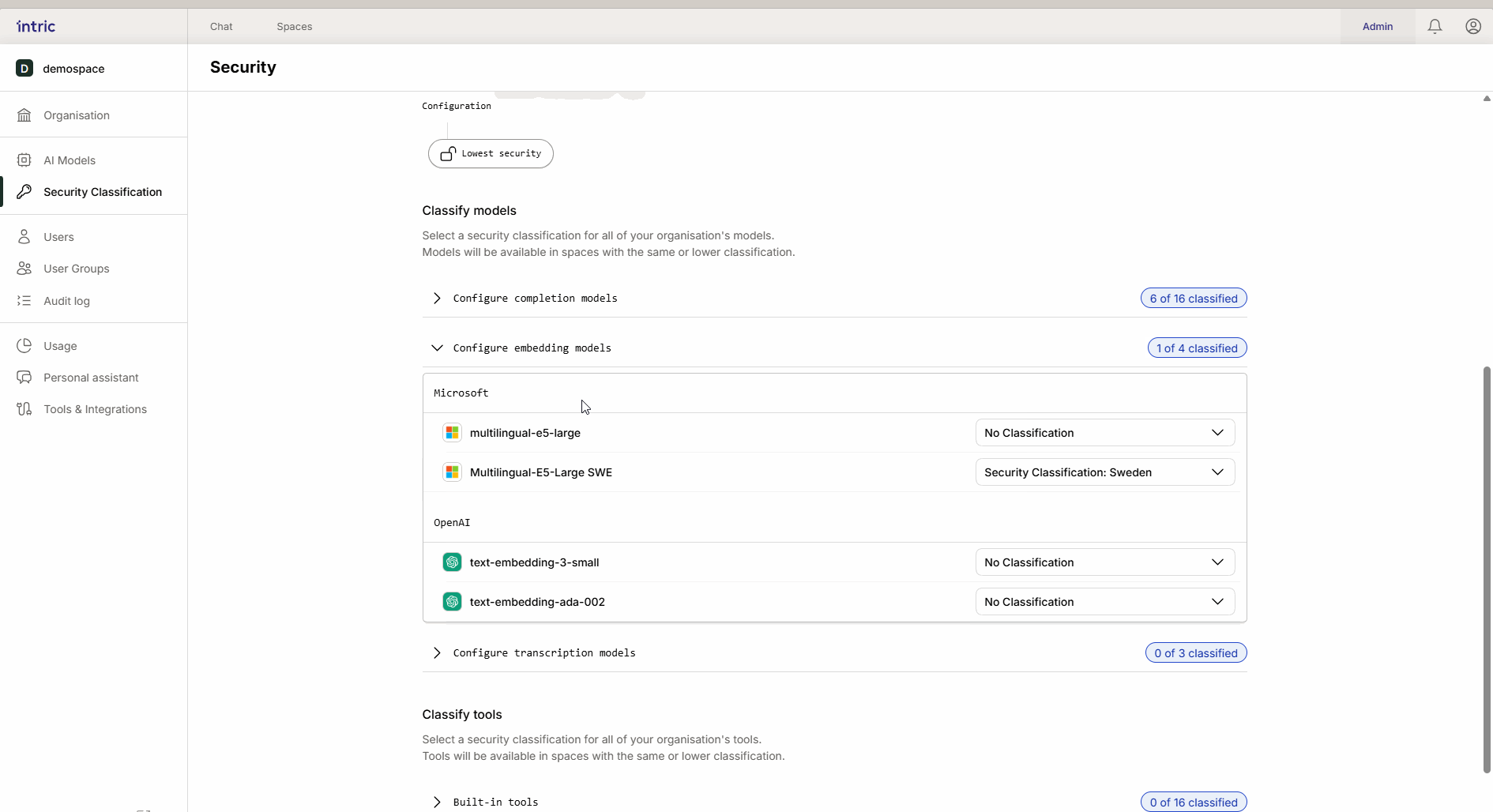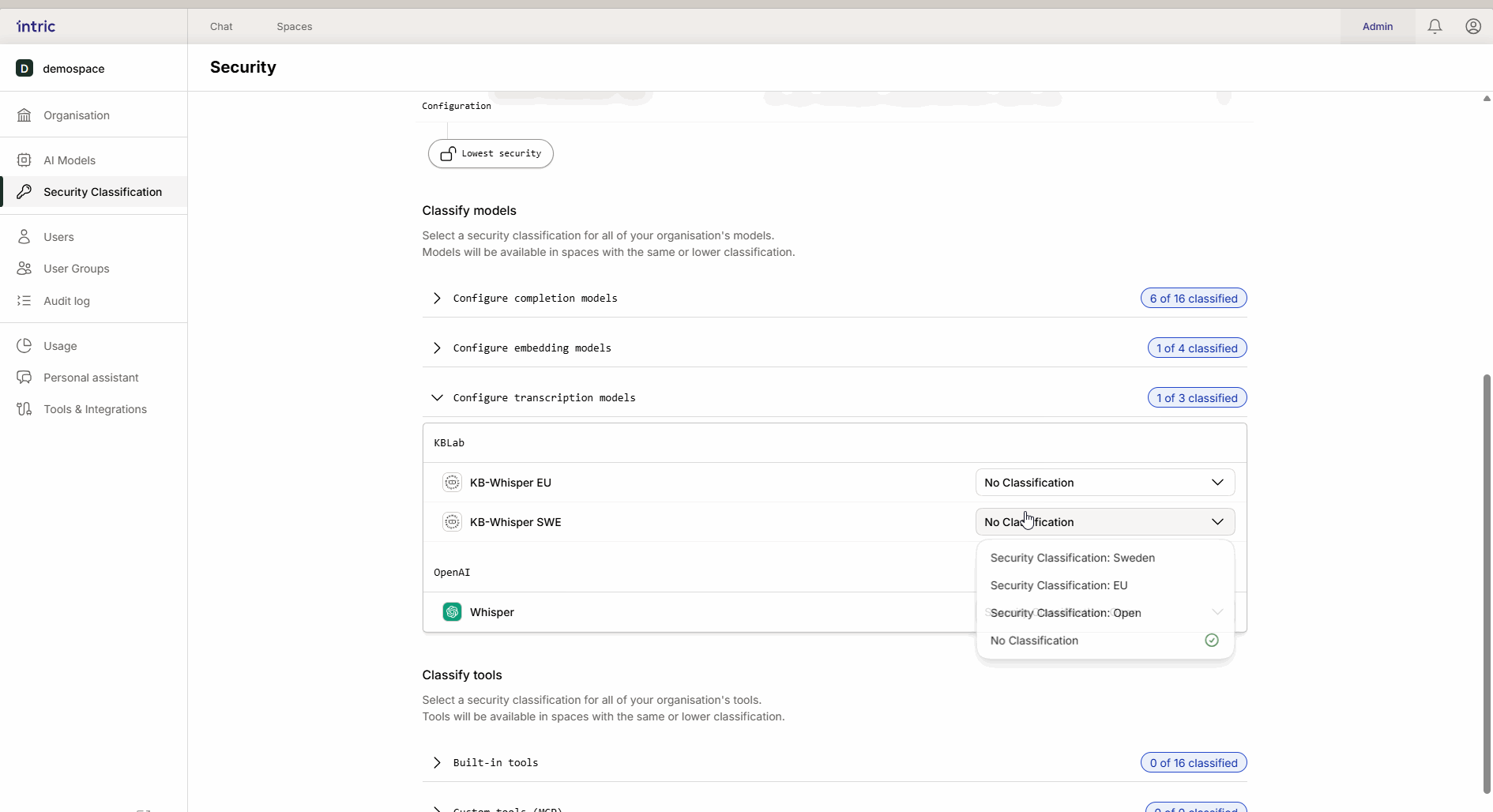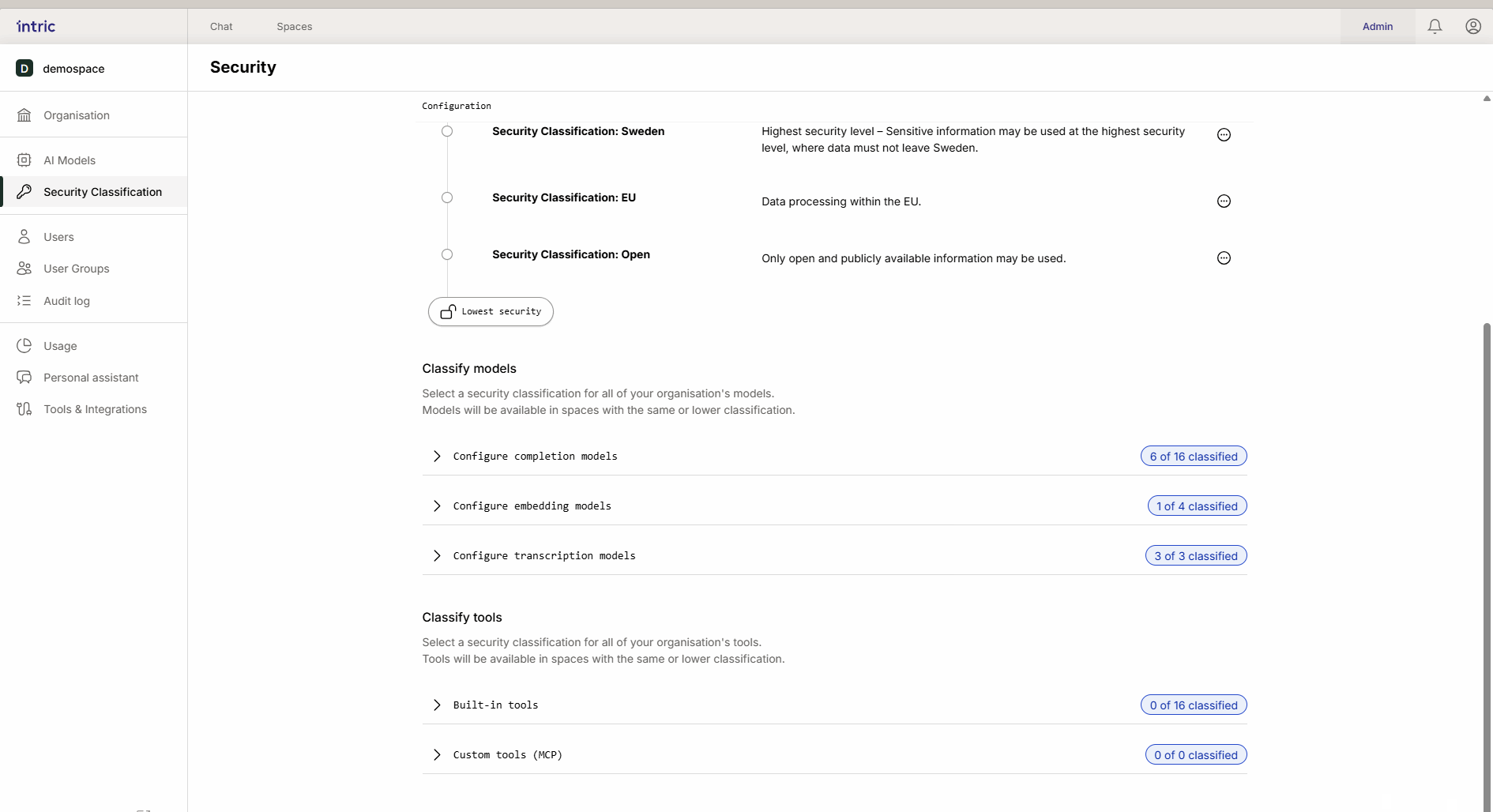
3. Transkriptionsmodelle
Werden verwendet, um Sprache in Text zu konvertieren (z. B. wenn du eine Audiodatei von einem Meeting hochlädst). Während das Sprachmodell den Text analysiert, ist es das Transkriptionsmodell, das die Datei zuerst “anhört”. Wenn ein Meeting sensible Informationen enthält, muss das Transkriptionsmodell entsprechend klassifiziert werden.